Cơ bản về ANN - Artificial Neural Network
Mục tiêu của bài viết này là nhằm cung cấp cho bạn đọc kiến thức cơ sở về mạng neuron nhân tạo (Artificial Neural Network - ANN). Đối với bài viết cơ sở tri thức này, mình sẽ dùng ANN để xử lý bài toán phân loại (classification).
Mục tiêu của bài toán Classification (Phân loại)
Trong machine learning, Classification là bài toán dự đoán một "nhãn" (label) hoặc một "lớp" (class) rời rạc cho một đầu vào dữ liệu cụ thể.
Bản chất của bài toán
Mục tiêu cốt lõi của ANN trong phân loại là tìm ra một Hàm xấp xỉ sao cho với mỗi đầu vào , giá trị đầu ra khớp nhất với nhãn thực tế.
Input (): Một vector đặc trưng (ví dụ: tập hợp các điểm ảnh, hoặc các chỉ số tài chính của một khách hàng).
Output (): Một giá trị xác suất hoặc chỉ số lớp (ví dụ: 0 cho "Sạch", 1 cho "Spam").
Decision Boundary (Đường biên quyết định)
ANN cố gắng học cách vẽ ra các đường biên để phân chia không gian dữ liệu.
Nếu dữ liệu có thể tách biệt bằng một đường thẳng, ta gọi là Linearly Separable.
Nếu dữ liệu phức tạp (như hình xoắn ốc hoặc chồng lấn), ANN cần các lớp ẩn để tạo ra đường biên cong (phi tuyến).
Perceptron - Viên gạch nền móng của ANN
Perceptron là mô hình mạng nơ-ron đơn giản nhất, được Frank Rosenblatt giới thiệu vào năm 1958. Nó mô phỏng cách một nơ-ron sinh học tiếp nhận tín hiệu và quyết định có "kích hoạt" hay không.
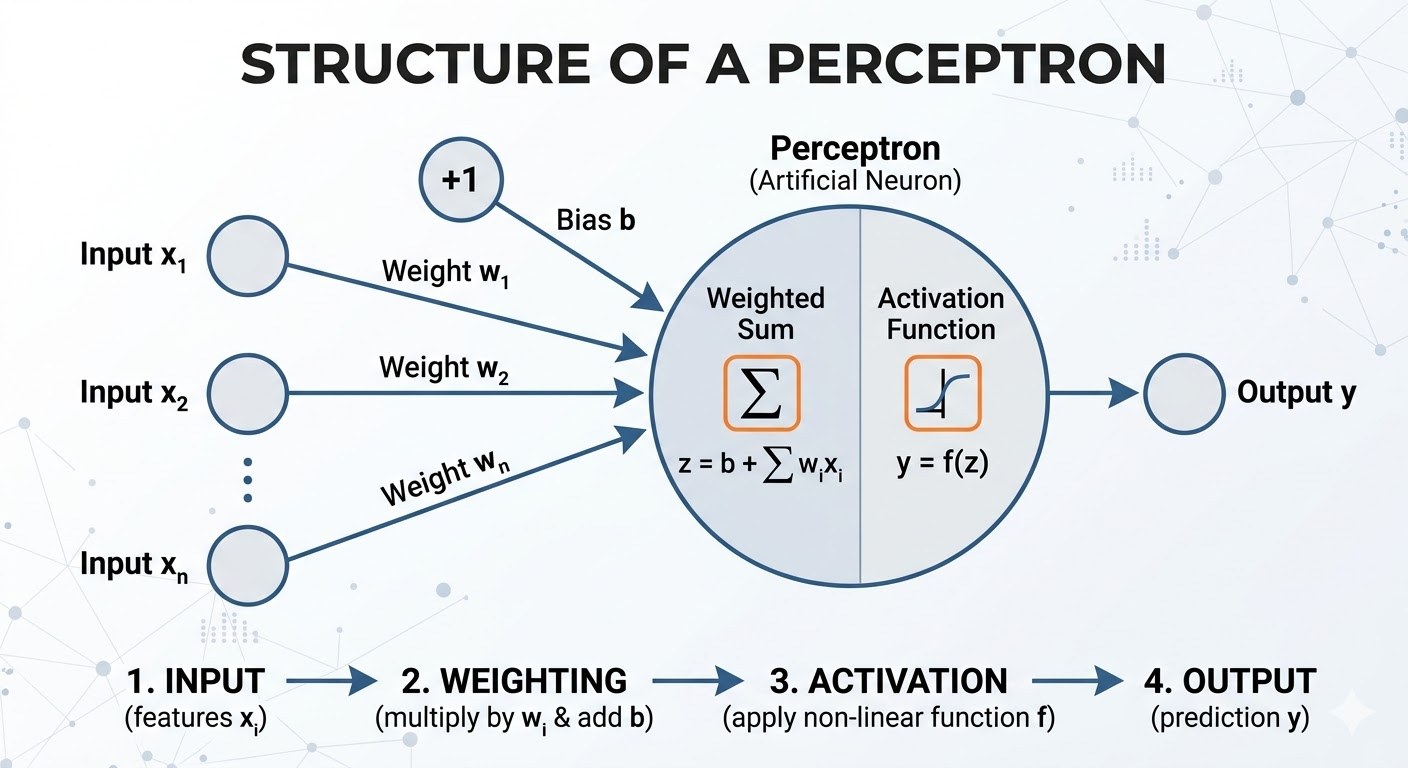
Kiến trúc của Perceptron
Một Perceptron bao gồm 4 thành phần chính:
Dữ liệu đầu vào (): Các đặc trưng của dữ liệu.
Trọng số (): Thể hiện mức độ quan trọng của từng đặc trưng.
Độ lệch (Bias - ): Cho phép dịch chuyển đường quyết định lên xuống, giúp mô hình linh hoạt hơn.
Hàm kích hoạt (Activation Function): Quyết định đầu ra cuối cùng.
Cơ chế Feed Forward (Lan truyền tiến)
Quá trình này là quá trình "chuyển hóa" thông tin đầu vào để thành thông tin quyết định (phân loại) ở đầu ra, gồm hai bước tính toán:
Bước 1: Tính tổng hàm truyền (Linear Sum)
Nếu xem như một vector , và như vector , ta đơn giản hóa công thức lại thành: . Đây thực chất có dạng một đường thẳng () chia cắt không gian thành 2 miền âm và dương.
Bước 2: Áp dụng hàm kích hoạt
Từ "đường thẳng" ở bước 1, mặt phẳng sẽ được chia làm 2 miền, miền các điểm làm cho và một miền . Trong Perceptron cổ điển, người ta dùng hàm bước (Step Function) để biểu diễn:
Tuy nhiên, loại hàm bước này có nhược điểm chí tử: nó "quá cứng nhắc" (chỉ có 0 hoặc 1) và quan trọng nhất là không có đạo hàm hữu ích để dùng cho thuật toán Lan truyền ngược (Backpropagation sẽ nói ngay mục sau). Để mạng nơ-ron có thể học được các cấu trúc dữ liệu phức tạp, chúng ta thay thế Hàm Bước (Step Function) bằng các hàm kích hoạt phi tuyến "mềm" hơn:
Hàm Sigmoid: Đây là hàm kích hoạt kinh điển trong các bài toán Classification nhị phân.
Công thức:
Đặc điểm: Nén mọi giá trị đầu vào về khoảng , có thể được hiểu là xác suất (ví dụ: 0.8 tương đương 80% khả năng là ảnh con mèo).
Hàm ReLU (Rectified Linear Unit)
Hiện nay, ReLU là hàm phổ biến nhất trong các mạng nơ-ron sâu (Deep Learning).
Công thức:
Đặc điểm: Hàm này cực kỳ đơn giản về tính toán và giúp vượt qua hiện tượng "triệt tiêu đạo hàm" (vanishing gradient) mà Sigmoid hay gặp phải.
Cơ chế Back Propagation (Lan truyền ngược)
Đối với mỗi thông tin đầu vào , đi cùng với nó sẽ có một thông tin trọng số để đánh giá tầm quan trọng của . Quá trình "học" thực chất là quá trình căn chỉnh các giá trị để sao cho đánh giá chính xác nhất tầm quan trọng của đầu vào . Như vậy, thực chất là ta cần giải một bài toán tối ưu toán học đơn giản:
Mô hình hóa: Perceptron là một hàm số đa biến . Nhiệm vụ của nó là ánh xạ đầu vào thành một giá trị dự báo .
Đo lường sai lệch (Loss Function): Với tập dữ liệu đã đánh nhãn , chúng ta cần biết hàm số trên "tệ" đến mức nào. Ta sử dụng các hàm mất mát Mean Squared Error (MSE): với là nhãn thực tế và là gia trị mạng dự đoán.
Định nghĩa Hàm mất mát trung bình (thường gọi là Cost Function ) trên tập dữ liệu có mẫu . Trong đó là nhãn thực tế và là giá trị dự đoán của điểm dữ liệu thứ .
Mục tiêu của chúng ta là tìm bộ trọng số sao cho hàm mất mát trung bình đạt giá trị nhỏ nhất (Global Minimum). Theo lý thuyết giải tích, để tìm cực trị của một hàm số, ta chỉ cần lấy đạo hàm và giải phương trình bằng 0:
Nếu giải được, ta có ngay kết quả tối ưu tuyệt đối chỉ trong một bước tính toán. Mặc dù lý thuyết là vậy, nhưng đối với mạng Perceptron (khi dùng hàm phi tuyến) và đặc biệt là mạng đa tầng (MLP), việc giải phương trình trở nên bất khả thi vì:
Tính phi tuyến (Non-linearity): Sự xuất hiện của các hàm kích hoạt như Sigmoid, ReLU khiến phương trình đạo hàm trở thành phương trình phi tuyến phức tạp, không có công thức nghiệm tổng quát (Closed-form solution).
Số lượng tham số khổng lồ: Trong các mạng ANN thực tế, có thể chứa hàng triệu biến số. Việc nghịch đảo ma trận hoặc giải hệ phương trình hàng triệu ẩn là cực kỳ tốn kém về tài nguyên tính toán ().
Điểm yên ngựa và cực tiểu địa phương: Hàm trong Deep Learning thường không lồi (Non-convex), có rất nhiều điểm mà đạo hàm bằng 0 nhưng không phải là điểm thấp nhất.
Gradient Descent: Chiến thuật "Dò đường trong bóng tối"
Vì không thể "nhìn một phát thấy ngay" điểm đáy thung lũng (giải phương trình), chúng ta chọn cách tiếp cận lặp (Iterative) bằng Gradient:
Gradient là gì? Nó là vector chứa các đạo hàm riêng, chỉ hướng dốc nhất đi lên của hàm số tại điểm hiện tại.
Chiến thuật: Nếu không giải được điểm đáy, ta sẽ đi từng bước nhỏ ngược hướng với Gradient. Mỗi bước đi, ta lại tính lại độ dốc mới và điều chỉnh hướng đi.
Trong đó (Learning Rate) là độ lớn của bước chân.
Gradient Descent không cho ta đáp án ngay lập tức như giải phương trình đạo hàm bằng 0, nhưng nó là một thuật toán xấp xỉ cực kỳ hiệu quả, có thể xử lý được các hàm số phi tuyến phức tạp và dữ liệu quy mô lớn mà các phương pháp giải tích "đầu hàng".
Demo - Perceptron
Mạng đa tầng (Multi-Layer Perceptron - MLP)
Tại sao Perceptron đơn tầng là chưa đủ?
Perceptron đơn giản (single-layer) chỉ có thể phân loại dữ liệu tuyến tính – nghĩa là các nhóm dữ liệu phải có thể tách biệt bằng một đường thẳng (trong 2D) hoặc một siêu phẳng (trong không gian cao chiều hơn).
Ví dụ kinh điển minh họa hạn chế này là bài toán XOR (cổng logic XOR): Với các điểm dữ liệu và , ta không bao giờ có thể vẽ một đường thẳng duy nhất để chia tách hai nhóm này.
Giải pháp: Ta cần uốn cong không gian đặc trưng (feature space) để tạo ra ranh giới phân loại phi tuyến (non-linear). Cách duy nhất là xếp chồng nhiều lớp nơ-ron lên nhau và sử dụng hàm kích hoạt phi tuyến (như ReLU, Sigmoid, Tanh). Đó chính là ý tưởng cốt lõi của Multi-Layer Perceptron (MLP).
Kiến trúc mạng đa tầng (Fully Connected)
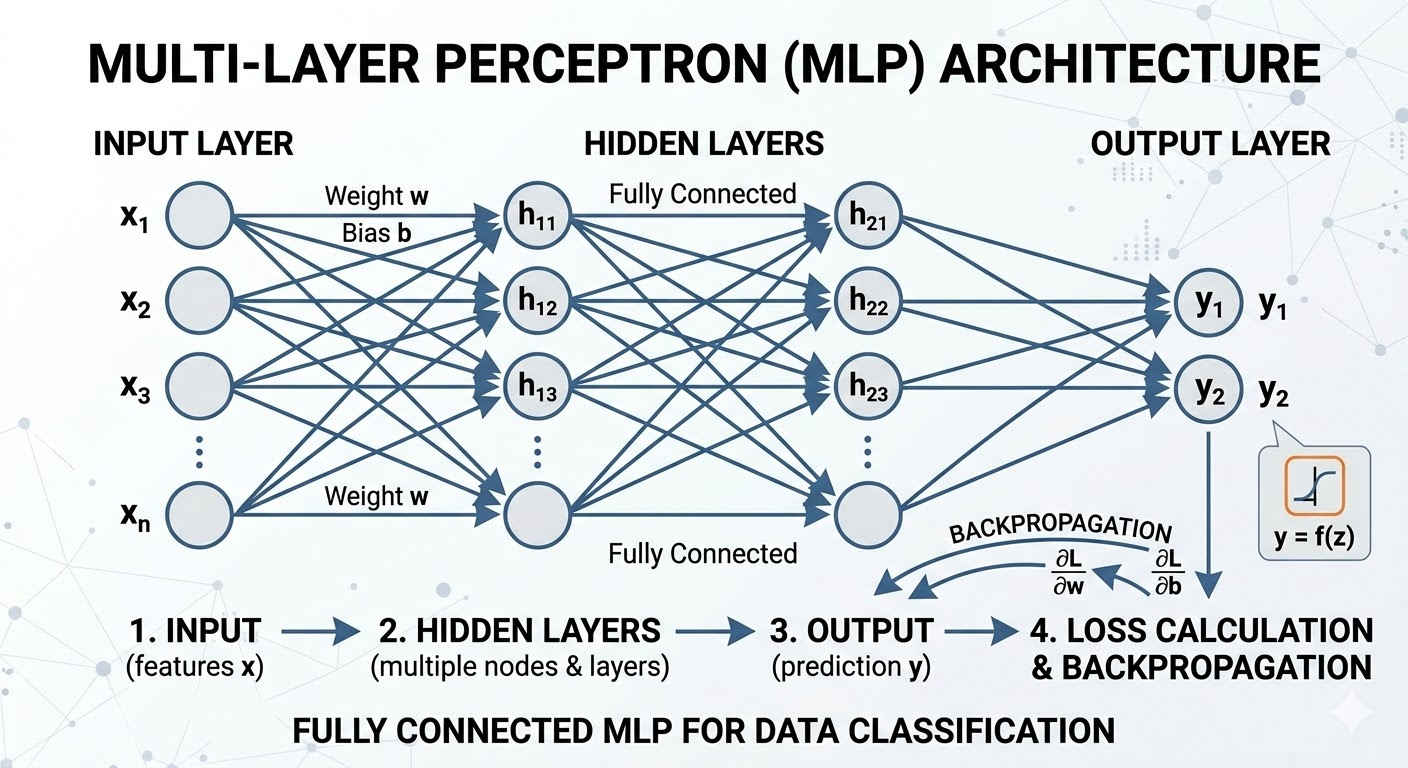
Một mạng MLP điển hình gồm ba loại lớp:
Input Layer: Nhận dữ liệu đầu vào (các đặc trưng của mẫu). Không có tính toán, chỉ truyền thẳng.
Hidden Layers (các lớp ẩn): Mỗi lớp ẩn trích xuất đặc trưng phức tạp hơn từ lớp trước. Số lớp ẩn và số nơ-ron trong mỗi lớp là siêu tham số (hyperparameters) mà chúng ta cần điều chỉnh.
Output Layer: Đưa ra kết quả cuối cùng.
Với bài toán hồi quy: thường 1 nơ-ron (hoặc không activation).
Với phân loại: số nơ-ron bằng số lớp, thường dùng Softmax để ra xác suất.
Trong MLP fully connected (kết nối đầy đủ – phổ biến nhất), mọi nơ-ron ở lớp trước kết nối với mọi nơ-ron ở lớp sau.
Cơ chế Feed Forward:
Trong thực tế, ta không tính toán cho từng nơ-ron riêng lẻ mà tính toán cho toàn bộ một lớp cùng một lúc.
Quy ước ký hiệu:
: Tổng số lớp trong mạng.
: Số lượng nơ-ron trong lớp .
: Vector đầu ra của lớp , kích thước . (Lưu ý là input).
: Ma trận trọng số nối từ lớp sang lớp . Kích thước là .
: Vector bias của lớp , kích thước .
Với mỗi lớp từ :
Tính tổng tuyến tính (Pre-activation):
Tính giá trị kích hoạt (Activation):
Trong đó là hàm phi tuyến như ReLU hoặc Sigmoid được áp dụng cho từng phần tử.
Tại sao lại dùng Ma trận?
Thay vì tính từng nơ-ron riêng lẻ, ta dùng phép nhân ma trận để tính toàn bộ lớp cùng lúc. Việc này giúp tính toán cực kỳ hiệu quả trên GPU/TPU.
Cơ chế Backpropagation:
Mục tiêu của Backpropagation là tính gradient (đạo hàm riêng phần) của hàm mất mát theo tất cả trọng số và bias của mọi lớp, để chúng ta biết nên điều chỉnh chúng theo hướng nào và bao nhiêu.
Hàm mất mát chỉ phụ thuộc trực tiếp vào output của lớp cuối cùng . Nhưng lại phụ thuộc vào phụ thuộc vào , phụ thuộc vào , … và cứ thế ngược về lớp đầu tiên. Do đó, để tính đạo hàm của theo một trọng số (hoặc bias) nằm ở bất kỳ lớp nào, ta phải nhân chuỗi tất cả các đạo hàm liên quan theo quy tắc dây chuyền (Chain Rule):
Để thuận tiện cho việc tính toán, ta định nghĩa sai số (error term) . Đây là một mẹo cực kỳ thông minh:
chính là giá trị trước khi kích hoạt (pre-activation): .
Sau khi tính , ta có thể tính ngay gradient của trọng số và bias chỉ bằng vài phép nhân ma trận đơn giản, mà không cần viết lại toàn bộ chuỗi đạo hàm dài dòng mỗi lần.
mang ý nghĩa vật lý: “Lỗi của lớp muốn thay đổi theo hướng nào để giảm tổng loss”.
Nói cách khác, là “cầu nối” giữa hàm mất mát và toàn bộ các trọng số/bias của lớp đó. Nhờ định nghĩa này, công thức cập nhật trọng số trở nên rất gọn và dễ triển khai.
Các bước tính Back Propagation bây giờ có thể "bẻ ra" thành nhiều phần đơn lẻ như sau:
Bước 1: Tính sai số của lớp cuối (output layer), giả sử hàm mất mát là MSE (hoặc Cross-Entropy), ta có:
Ở đây, là nhân từng phần tử của hai vector.
Bước 2: Lan truyền sai số ngược về các lớp trước với mỗi lớp
Công thức này cho thấy lỗi được “phân phối ngược” từ lớp sau về lớp trước, nhân với đạo hàm của hàm kích hoạt để biết mức độ ảnh hưởng.
Bước 3: Tính gradient cho trọng số và bias
Bước 4: Sau khi có Gradient cho toàn bộ các lớp, ta thực hiện cập nhật trọng số (Gradient Descent), với là learning rate:
Demo - MLP 1
Đây là một demo lấy cảm hứng từ ANN Playground của Tensor Flow
Demo - MLP 2
Demo này cho phép bạn viết 1 con số từ 0 - 9 rồi máy sẽ tự đoán con số viết tay của bạn là số mấy. Ban đầu máy có thể sẽ dự đoán sai, tuy nhiên nếu bạn cố gắng train nhiều lần (phần dưới) máy sẽ ngày một thông minh hơn và dự đoán tốt hơn.
Mạng neural được thiết kế bằng cách lấy thông tin grayscale từ tất cả 8x8 điểm để đưa vào training, nghĩa là lớp input sẽ có 64 neuron, một mạng ẩn hidden có 32 neuron và output có 10 neuron chỉ định dự đoán, mỗi neuron đại diện cho tỷ lệ phần trăm cho mối dự đoán từ 0 đến 9. Bạn có quyền thay đổi số neuron trong mạng ẩn để xem hiệu quả của training.
Lời bàn: Learning rate và Hyperparameters – Những yếu tố quyết định thành bại
Trong thực tế, mạng neuron không tự động học tốt chỉ vì có công thức đúng. Hiệu suất thực tế phụ thuộc rất lớn vào việc chọn siêu tham số (hyperparameters) phù hợp.
1. Learning rate (η) – Tốc độ học – là siêu tham số quan trọng nhất
Quá nhỏ (ví dụ ): Mạng học rất chậm, có thể mất hàng nghìn epoch mới hội tụ, thậm chí kẹt ở điểm yên ngựa (saddle point) hoặc cực tiểu cục bộ.
Quá lớn (ví dụ ): Gradient descent "nhảy cóc" qua điểm tối ưu, loss dao động mạnh hoặc thậm chí diverge (loss tăng vọt lên vô cực).
Giá trị hợp lý: Thường bắt đầu từ 0.001 đến 0.1, tùy bài toán. Với ReLU và Adam optimizer, thường ổn.
Hiện nay, hầu hết mọi người không dùng learning rate cố định nữa, mà dùng các optimizer thông minh như:
Adam (Adaptive Moment Estimation): tự động điều chỉnh learning rate cho từng tham số.
RMSprop, AdamW, Lion… – giúp hội tụ nhanh và ổn định hơn.
2. Các hyperparameters khác cần chú ý
Số lớp ẩn và số neuron mỗi lớp: Nhiều lớp/neuron → mạng mạnh hơn, nhưng dễ overfitting và tốn tài nguyên.
Batch size: Batch nhỏ (32–128) thường giúp generalize tốt hơn, nhưng chậm hơn.
Activation function: ReLU là lựa chọn mặc định hiện nay, nhưng có thể thử Leaky ReLU, GELU nếu gặp vấn đề dying ReLU.
Regularization: Dropout, L2 regularization (weight decay) để tránh overfitting.
Epochs và Early Stopping: Dừng huấn luyện khi validation loss không còn giảm.
Tóm lại: Công thức toán học chỉ là nền tảng. Khả năng điều chỉnh hyperparameters mới là kỹ năng thực sự phân biệt người mới và người có kinh nghiệm trong machine learning.
More from AI & ML
- RL - Từ TD-Learning đến Q-Learning
- RL - Phương pháp Actor Critic
- Reinforcement Learning - Học theo Chính Sách (Policy Gradient)
- JEPA: Kiến Trúc Dự Đoán Không Gian Ẩn và Con Đường Đến Trí Tuệ Thực Sự
- Reinforcement Learning - Bài mở đầu
- Multi-Armed Bandits: Từ Greedy đến UCB rồi đến Exp3
- Aritificial Neural Network: Bản chất Xác suất phía sau Bài toán Hồi quy
- NEAT (NeuroEvolution of Augmenting Topologies)- Nhiệm vụ hạ cánh tàu vũ trụ
- Q-Learning căn bản - Nhiệm vụ hạ cánh tàu vũ trụ
- Singular Value Decomposition (SVD) Demo
- Thuật toán K-Means demo
Comments
No comments yet. Be the first to comment!