Reinforcement Learning - Học theo Chính Sách (Policy Gradient)
Review lại bài trước
Để bắt đầu bài viết này, chúng ta cần xem lại một số khái niệm cơ bản của Reinforcement Learning (RL) mà bạn đã làm quen ở bài trước.
Mô hình chuẩn của RL
Mọi bài toán RL, từ việc huấn luyện robot bước đi đến việc xây dựng một AI chơi cờ, đều dựa trên một mô hình tương tác vòng lặp không hồi kết:
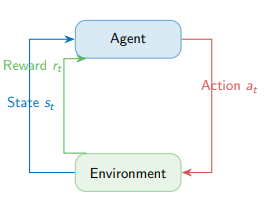
Agent (Tác tử): Là "bộ não", thực thể đưa ra các quyết định dựa trên những gì nó quan sát được.
Environment (Môi trường): Là thế giới xung quanh Agent, phản hồi lại các hành động của nó.
State (): Trạng thái hiện tại của Agent trong môi trường tại thời điểm .
Action (): Hành động mà Agent thực hiện tại thời điểm .
Reward (): Phần thưởng (hoặc hình phạt) mà Agent nhận được ngay sau khi thực hiện hành động và chuyển sang trạng thái mới .
Mục tiêu tối thượng của Agent không phải là ăn tối đa hóa ngay lập tức, mà là tối đa hóa tổng phần thưởng tích lũy (total reward) trong suốt quá trình tương tác.
Hai hướng tiếp cận chính: Value-based vs. Policy-based
Có hai tư duy chủ đạo để giúp Agent đạt được mục tiêu tối thượng đó:
Value-based (Tiếp cận dựa trên giá trị): Ở lộ trình này, Agent cố gắng học giá trị (Value) của các trạng thái hoặc các cặp trạng thái-hành động.
Ví dụ: Q-learning hay DQN.
Tư duy: "Nếu tôi ở trạng thái này và làm hành động kia, tôi sẽ thu được bao nhiêu lợi ích về lâu dài?". Sau khi biết giá trị của mọi hành động, Agent chỉ việc chọn cái nào có giá trị lớn nhất (argmax).
Hạn chế: Gặp khó khăn khi không gian hành động quá lớn hoặc là không gian liên tục (continuous), vì việc tìm hành động tốt nhất qua hàm
argmaxlúc này trở nên cực kỳ đắt đỏ về mặt tính toán và không khả vi.
Policy-based (Tiếp cận dựa trên chính sách): Đây chính là trọng tâm của bài viết này. Thay vì học hàm giá trị để suy ra hành động, chúng ta học trực tiếp Chính sách
Ví dụ: Thuật toán REINFORCE, PPO, A2C.
Tư duy: "Tôi sẽ học một hàm số để trả về trực tiếp xác suất chọn hành động khi đang ở trạng thái ".
Ưu điểm: Phương pháp này cực kỳ linh hoạt, có thể hoạt động hiệu quả với mọi không gian hành động (rời rạc hoặc liên tục) và đặc biệt là chính sách có tính khả vi, cho phép chúng ta sử dụng các kỹ thuật tối ưu hóa mạnh mẽ như Gradient Ascent.
Bài toán Grid-World
Đây là bài toán làm ví dụ xuyên suốt cả bài viết. Hãy tưởng tượng một Agent đang ở trong một mê cung ô lưới (GridWorld) như hình dưới đây:
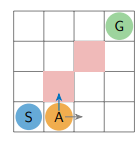
Mục tiêu của Agent là tìm đường đến G mà có thể tối đa hóa phần thưởng nhận được với các thông tin sau:
S (Start): Điểm bắt đầu.
G (Goal): Đích đến - nơi Agent nhận được phần thưởng hậu hĩnh (). Khi đến đích thì giả lập kết thúc.
Ô đỏ: Đi vào sẽ bị phạt nặng (phần thưởng )
Ô trắng: Đi vào sẽ bị phạt nhẹ (phần thưởng )
Luật chơi: Agent tại một ô bất kỳ có thể đi 1 trong 4 hướng: Lên, Xuống, Trái, Phải để sang ô mới.
Định nghĩa Policy
Trong RL, Policy () chính là thực thể đóng vai trò quyết định hành động dựa trên những gì Agent quan sát được từ môi trường. Để máy tính có thể học và cải thiện được chính sách này, chúng ta cần cụ thể hóa nó dưới dạng các hàm toán học. Có hai cách cơ bản để mô tả một chính sách:
Deterministic Policy (Chính sách định mệnh): Đây là dạng đơn giản nhất, trong đó Agent luôn chọn một hành động cố định cho mỗi trạng thái cụ thể: . Giống như một quy tắc cứng nhắc: "Nếu thấy đèn đỏ, chắc chắn phải dừng lại".
Stochastic Policy (Chính sách ngẫu nhiên): Ở dạng này, chính sách không trả về một hành động duy nhất mà trả về một phân phối xác suất trên tập hợp các hành động: . Nghĩa là tại trạng thái , Agent có thể chọn hành động với xác suất nào đó.
Để có thể dùng các thuật toán tối ưu hóa (như Gradient Ascent), chúng ta cần biến Policy thành một hàm số phụ thuộc vào một bộ tham số (ví dụ: các trọng số trong mạng Neural). Lúc này, policy được ký hiệu là . Lúc đó, khi chúng ta thay đổi giá trị của , xác suất chọn các hành động tại các trạng thái sẽ thay đổi theo. Như vậy, công việc của chúng ta bây giờ là đi tìm bộ tham số sao cho chính sách tạo ra những hành động mang lại tổng phần thưởng lớn nhất. Đây chính là nền tảng của họ thuật toán Policy Gradient: Thay vì đi tìm giá trị của trạng thái, chúng ta đi tính toán gradient của hàm mục tiêu theo tham số để trực tiếp nâng cấp chính sách của mình. Ví dụ chúng ta có thể chọn hàm softmax thông qua mạng neural để tính: , sau đó qua qua trình huấn luyện, chúng ta điều chỉnh dần để tối ưu dần hàm .
Hàm mục tiêu
Trong RL, mục tiêu của chúng ta không phải là tối ưu một hành động đơn lẻ, mà là tối ưu cả một quá trình tương tác. Ta định nghĩa Hàm mục tiêu , đại diện cho kỳ vọng về tổng phần thưởng mà Agent nhận được khi tuân theo chính sách :
Trong đó:
: Được gọi là một quỹ đạo (trajectory) hoặc một Episode. Nó là chuỗi các trạng thái, hành động và phần thưởng mà Agent trải qua từ đầu đến cuối. Đối với bài toán grid world thì trajectory có thể là tập hợp các bước đã đi cùng với phần thưởng kèm theo mỗi bước kể từ lúc agent bắt đầu đến lúc kết thúc.
: Tổng phần thưởng tích lũy (Return) của quỹ đạo .
: Hệ số chiết khấu (discount factor), giúp cân bằng giữa giá trị tức thời và giá trị tương lai. Lý do ta đưa hệ số chiết khấu là để giá trị hội tụ (chuỗi hình học)
: Ký hiệu Kỳ vọng (Expectation). Vì môi trường và chính sách có tính ngẫu nhiên, Agent có thể đi theo nhiều quỹ đạo khác nhau. Ở đây, có ý nghĩa là được lấy mẫu từ phân phối do policy (và môi trường) sinh ra. là giá trị trung bình mà Agent mong đợi nhận được nếu thực hiện nhiệm vụ vô số lần với cùng một .
Để tối ưu hóa, chúng ta sử dụng phương pháp Gradient Ascent nhằm cập nhật theo hướng tăng tiến của hàm mục tiêu:
Trajectory (quỹ đạo)
Mình đã nhắc đến điều này ở bên trên và nhắc lại ở đây vì muốn các bạn phải hiểu thật rõ ràng trajectory là gì. Một Trajectory , hay còn gọi là quỹ đạo, là một chuỗi các diễn biến từ lúc Agent bắt đầu cho đến khi kết thúc. Đối với bài toán grid world thì trajectory có thể là tập hợp các bước đã đi kể từ lúc agent bắt đầu đến lúc kết thúc (đi đến mục tiêu). Tuy nhiên, đối với một số trường hợp, ví dụ như trò chơi vô hạn như giữ gậy thăng bằng, chúng ta có thể xác định một độ dài nhất định cho trajectory mà không nhất thiết phải chờ tới trạng thái kết thúc mới tạo nên một trajectory:
Đi kèm với mỗi bước đi là một phần thưởng , tạo nên tổng lợi nhuận . Dựa trên tính chất Markov (trạng thái tiếp theo chỉ phụ thuộc vào trạng thái và hành động hiện tại):
Xác suất để quỹ đạo xảy ra khi Agent tuân theo chính sách là tích của các xác suất thành phần:
Khi nhìn vào công thức này, ta thấy một chi tiết cực kỳ thú vị:
và là các thành phần thuộc về môi trường (Environment Dynamics). Agent hoàn toàn không biết và không thể điều khiển được quy luật vật lý hay logic này của môi trường.
Chỉ có là thành phần duy nhất phụ thuộc vào tham số của Agent.
Mục tiêu của chúng ta là tính đạo hàm của hàm mục tiêu:
Trong đó, là tổng trên tất cả các quỹ đạo có thể xảy ra dưới phần phối được sinh ra bởi policy và môi trường. Để ý là sở dĩ ta có đẳng thức trên là vì:
Reward bị chặn do
Policy là hàm được chọn sao cho là hàm trơn (softmax, ...)
Vấn đề nan giải ở đây là chúng ta không thể tính trực tiếp đạo hàm này vì chúng ta không biết . Cụ thể hơn, ta không biết các xác suất chuyển trạng thái của môi trường. Trong thực tế, môi trường thường là một "hộp đen" (Black-box), ta chỉ có thể tương tác và lấy mẫu chứ không có công thức cụ thể. Tuy nhiên chúng ta lại tìm ra được một giải pháp rất thú vị cho vấn đề này thông qua Log-Derivative trick.
Log-Derivative trick
Dựa trên quy tắc đạo hàm hàm hợp: , ta có thể viết lại:
Áp dụng vào đạo hàm của hàm mục tiêu :
Khi ta khai triển từ công thức trên:
Do ta lấy đạo hàm theo nên:
(vì không phụ thuộc ).
(vì không phụ thuộc ).
Cuối cùng ta có:
Tuyệt vời! Sau khi đưa về dạng , thành phần không biết đã trở thành tính đạo hàm của log-policy tại mỗi bước thời gian, mà là thứ mà ta có thể biết được vì chính chúng ta là người thiết kế ra nó.
Định lý Policy Gradient (Policy Gradient Theorem)
Kết hợp tất cả những mảnh ghép từ đầu bài viết, chúng ta đi đến công thức tổng quát của Định lý Policy Gradient ở dạng quỹ đạo (Trajectory form):
Về bản chất, công thức này đang thực hiện một quy tắc "thưởng - phạt" rất logic:
: Đây là hướng để tăng xác suất chọn hành động tại trạng thái .
: Đây là trọng số (vừa là độ lớn, vừa là chiều).
Nếu quỹ đạo có tổng phần thưởng dương và rất lớn, ta sẽ đẩy mạnh xác suất của tất cả các hành động trong quỹ đạo đó lên.
Nếu âm hoặc rất nhỏ, ta sẽ giảm xác suất của các hành động này xuống.
Nói cách khác: "Nếu hành trình này mang lại kết quả tốt, hãy ghi nhớ và thực hiện các hành động này thường xuyên hơn trong tương lai".
Reward-To-Go
Mặc dù công thức trên đúng về mặt toán học, nhưng nó lại gặp một vấn đề nghiêm trọng về mặt logic thực tế và hiệu suất huấn luyện, đó là Tính nhân quả (Causality). Hãy nhìn vào một hành động tại thời điểm . Trong công thức trên, hành động đang bị nhân với toàn bộ tổng phần thưởng của cả hành trình.
bao gồm cả những phần thưởng từ quá khứ (từ thời điểm đến ).
Ở đây, có một điều phi lý là một hành động thực hiện ở hiện tại không thể nào thay đổi được những gì đã xảy ra trong quá khứ. Việc bắt hành động "chịu trách nhiệm" cho những phần thưởng quá khứ sẽ tạo ra rất nhiều nhiễu (noise) và làm tăng phương sai (variance) cho quá trình học.
Để sửa lỗi này, chúng ta thay thế bằng Reward-to-go — chỉ tính tổng phần thưởng từ thời điểm hành động được thực hiện cho đến khi kết thúc:
Để dễ hình dung hãy xem hình minh họa dưới đây theo trục thời gian để thây Reward-to-Go chỉ được tính kể từ thời điểm trở đi
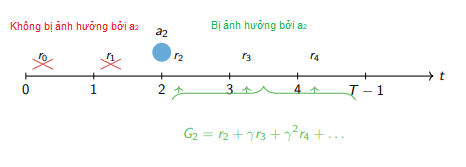
Lúc này, công thức Policy Gradient được tinh chỉnh lại thành:
Ở đây, chỉ còn một nút thắt, đó là ta không thể tính được kỳ vọng chính xác (vì không thể duyện được mọi - không gian có thể quá lớn). Vì thế ta thay kỳ vọng bằng trung bình mẫu (Monte Carlo). Lấy quỹ đạo độc lập:
Sau đó, ta xấp xỉ gradient:
Đây chính là REINFORCE estimator, đó chính là tư tưởng của thuật toán REINFORCE tiếp theo dưới đây.
Thuật toán REINFORCE (Williams, 1992)
Dưới đây là chi tiết thuật toán, mình sẽ dùng tiếng Anh, để cho các bạn quen mắt với các từ khóa for, do, ...
Input: Policy , learning rate
for each episode do:
Collect trajectory using
for do:
Compute Reward-to-Go:
end for
Update:
end for
Để dễ hình dung việc tính toán của thuật toán, hãy xem một ví dụ tính toán cụ thể cho bài toán Gridworld bên trên như sau:
Bước 1: Thiết lập
Để máy tính hiểu được chính sách, ta thường dùng một mạng neural đơn giản hoặc một hàm tuyến tính để đại diện cho .
Hàm Chính sách: .
Hàm softmax đảm bảo tổng xác suất của 4 hướng (Lên, Xuống, Trái, Phải) luôn bằng .
Learning Rate (): Thường chọn một giá trị nhỏ, ví dụ hoặc , để các bước cập nhật tham số diễn ra ổn định, không làm chính sách bị thay đổi quá đột ngột dẫn đến mất dấu đường đi tốt.
Hệ số chiết khấu (): Chọn để Agent ưu tiên những phần thưởng sớm.
Trajectory Length () : chiều dài của một trajectory.
Bước 2: Kịch bản trajectory 3 bước
Giả sử Agent bắt đầu từ điểm S:
: Từ , chọn đi Phải (). Nhận thưởng .
: Từ (vị trí A), chọn đi Lên (). Đây là hành động sai lầm dẫn vào ô đỏ. Nhận thưởng .
: Từ (trong ô đỏ), chọn đi Trái () để quay lại ô an toàn. Nhận thưởng .
Bước 3: Tính Reward-to-go ()
Chúng ta tính lùi từ bước cuối cùng:
Tại : .
Tại : .
Tại : .
Bước 4: Cập nhật
Cuối cùng thuật toán REINFORCE sẽ điều chỉnh bộ tham số qua công thức:
Nhận xét:
Dù cả 3 hành động đều nhận âm, nhưng mức độ "phạt" là khác nhau. Hành động trực tiếp dẫn vào ô đỏ () bị phạt nặng nhất (). Qua nhiều lần thử (Episodes), nếu Agent tìm được một quỹ đạo khác (ví dụ: đi Phải -> đi Phải) để tới đích nhận , lúc đó sẽ trở nên dương rất lớn. Khi đó, Gradient sẽ đảo chiều và "củng cố" (reinforce) những tham số giúp tăng xác suất của những hành động đúng đắn đó lên.
Thuật toán REINFORCE với baseline
Vấn đề của thuật toán REINFORCE
Từ phần trước, theo công thức ta có:
Đây là một Monte Carlo estimator của gradient. Điều đó có nghĩa là ta đang lấy mẫu một số trajectory từ phân phối sinh ra từ và chúng dùng để xấp xỉ một kỳ vọng trên toàn bộ không gian quỹ đạo. Tuy nhiên, mỗi trajectory có thể rất khác nhau làm cho dao động mạnh, từ đó gradient cũng bị dao động mạnh. hay nói cách khác, là estimator bị variance cao do:
Ta chỉ lấy hữu hạn mẫu
Mỗi trajectory là một “lịch sử ngẫu nhiên” khác nhau
Một hành động tại thời điểm bị nhân với toàn bộ mà lại chứa nhiều phần thưởng không liên quan trực tiếp đến hành động đó.
Khi variance cao, các giá trị dao động rất mạnh — có trajectory cho giá trị rất lớn, có trajectory lại rất nhỏ hoặc âm. Điều này khiến gradient update trở nên “hỗn loạn”, lúc thì nhảy rất mạnh, lúc thì gần như không đáng kể. Để ổn định hơn, ta chuẩn hóa tương đối bằng cách trừ đi một mốc tham chiếu baseline :
Ý nghĩa của việc này là thay vì dùng giá trị trực tiếp, ta chỉ quan tâm: "kết quả này tốt hơn hay kém hơn mức bình thường?". Ta cải tiến estimator:
Hình dưới cho thấy phân phối của gradient trước và sau khi dùng baseline.
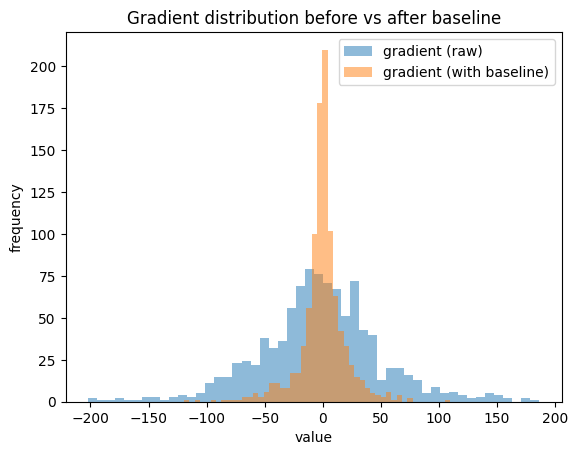
Khi không có baseline, gradient có độ phân tán lớn, với nhiều giá trị cực đoan
Khi trừ baseline, phân phối co lại rõ rệt quanh 0
Điều này cho thấy Baseline không làm thay đổi dữ liệu đầu vào, mà làm ổn định tín hiệu học (gradient).
Liệu việc trừ có làm sai lệch (bias) gradient không? KHÔNG (unbiased).
Bắt đầu từ công thức Policy Gradient với baseline:
Dựa trên tính chất tuyến tính của kỳ vọng (), ta tách biểu thức thành hai phần:
Để chứng minh không bị chệch, ta phải chứng minh Thành phần Baseline bằng 0.
Xét thành phần Baseline. Ta đưa dấu tổng ra ngoài kỳ vọng và áp dụng Luật kỳ vọng lặp (Law of Iterated Expectations) để tách biệt trạng thái và hành động :
Xét biểu thức bên trong tại một trạng thái cố định , vì hoàn toàn không phụ thuộc vào hành động , nó được coi là một hằng số đối với phép lấy kỳ vọng theo . Ta đưa ra ngoài:
Khai triển kỳ vọng theo định nghĩa tổng xác suất:
Thay vào biểu thức:
Vì là một phân phối xác suất hợp lệ trên không gian hành động , tổng xác suất của nó luôn luôn bằng 1 với mọi :
Thay vào ta có:
Vì đạo hàm của hằng số 1 theo bằng 0, ta thu được:
Do mọi thành phần trong dấu tổng đều bằng 0, ta có:
Vậy:
Chứng minh hoàn tất. Việc thêm baseline không hề làm thay đổi giá trị kỳ vọng của Gradient.
Vậy chọn baseline thế nào?
Sau khi đã chứng minh được rằng việc trừ đi một baseline không làm chệch (bias) gradient, câu hỏi quan trọng nhất là:
Nên chọn như thế nào để tối ưu nhất?
Mục tiêu cốt lõi của baseline là giảm phương sai (variance). Một baseline tốt sẽ giúp Agent phân biệt được đâu là một hành động "thực sự tốt" so với mặt bằng chung, thay vì chỉ dựa vào những con số phần thưởng tuyệt đối đôi khi rất nhiễu.
Trong thực tế, lựa chọn phổ biến và hiệu quả nhất cho baseline chính là Hàm giá trị trạng thái (State-Value Function) đại diện cho kỳ vọng về tổng phần thưởng mà Agent sẽ nhận được nếu bắt đầu từ trạng thái tại thời điểm và tuân thủ theo chính sách cho đến khi kết thúc Episode.Trong thuật toán Policy Gradient, baseline tốt nhất là giá trị kỳ vọng của tổng phần thưởng tính từ trạng thái hiện tại:
Trong đó:
: Hàm tính giá trị trung bình của trạng thái khi Agent hành động dựa trên policy tham số
: Giá trị kỳ vọng khi Agent hành động theo chính sách , với điều kiện là Agent đang đứng tại trạng thái cụ thể vào thời điểm .
: Hệ số chiết khấu (), giúp cân bằng giữa phần thưởng tức thời và phần thưởng trong tương lai.
: Phần thưởng nhận được tại bước thứ .
Vấn đề là chúng ta không thể tính toán giá trị (hay ) một cách trực tiếp được, vì chúng ta không biết giá trị kỳ vọng thực sự của môi trường là bao nhiêu vì Agent không biết trước xác suất chuyển trạng thái hay toàn bộ các kịch bản phần thưởng có thể xảy ra. Do đó, chúng ta xem như một hàm số xấp xỉ có tham số ký hiệu là . Thay vì tính toán kỳ vọng trên lý thuyết, ta bắt hàm phải "học" từ chính những kết quả thực tế () mà Agent thu thập được.
Lúc này, trong mỗi bước lặp của thuật toán REINFORCE, chúng ta thực hiện hai nhiệm vụ song song:
Cập nhật Chính sách : Dùng hiệu số để điều chỉnh hành động. Hiệu số này cho biết hành động này mang lại "lợi thế" bao nhiêu so với mức trung bình.
Cập nhật Hàm giá trị : Điều chỉnh hàm sao cho dự đoán của nó ngày càng gần với phần thưởng thực tế hơn (thường bằng cách giảm thiểu sai số bình phương):
Thuật toán updated với baseline
Input: Policy , value funtion , learning rates
for each episode do:
Collect trajectory using
for do:
Compute Reward-to-Go:
end for
end for
Demo
Cuối cùng là Demo cho trò chơi Gridworld ở trên. Bạn sẽ trải nghiệm cả 3 phương pháp tính toán: . Trong demo, bạn sẽ có thể train theo từng phương pháp, chọn vào từng item, bạn sẽ nhìn thấy chi tiết toán cụ thể và simulation Agent di chuyển thế nào.
More from AI & ML
- RL - Từ TD-Learning đến Q-Learning
- RL - Phương pháp Actor Critic
- JEPA: Kiến Trúc Dự Đoán Không Gian Ẩn và Con Đường Đến Trí Tuệ Thực Sự
- Reinforcement Learning - Bài mở đầu
- Multi-Armed Bandits: Từ Greedy đến UCB rồi đến Exp3
- Cơ bản về ANN - Artificial Neural Network
- Aritificial Neural Network: Bản chất Xác suất phía sau Bài toán Hồi quy
- NEAT (NeuroEvolution of Augmenting Topologies)- Nhiệm vụ hạ cánh tàu vũ trụ
- Q-Learning căn bản - Nhiệm vụ hạ cánh tàu vũ trụ
- Singular Value Decomposition (SVD) Demo
- Thuật toán K-Means demo
Comments
No comments yet. Be the first to comment!