JEPA: Kiến Trúc Dự Đoán Không Gian Ẩn và Con Đường Đến Trí Tuệ Thực Sự
The next AI revolution won't come from making language models bigger — it will come from giving machines a model of the world. — Yann LeCun
Tại sao LLM là chưa đủ?
Kể từ khi GPT-3 xuất hiện vào năm 2020, Generative AI đã trở thành biểu tượng của một kỷ nguyên mới. Các mô hình ngôn ngữ lớn (LLM) như GPT-4, Gemini, hay Grok có thể soạn thơ, viết code, giải thích khái niệm phức tạp, và thậm chí thông qua các kỳ thi y khoa với điểm số đáng nể. Tuy nhiên, đằng sau vẻ ngoài ấn tượng đó ẩn chứa một nghịch lý cơ bản: sự thông minh bề mặt không đồng nghĩa với sự hiểu biết thực sự.
Trọng tâm của vấn đề nằm ở cơ chế học Autoregressive — phương pháp mà phần lớn các LLM và mô hình sinh ảnh hiện đại sử dụng. Về bản chất, Autoregressive modeling huấn luyện mô hình để dự đoán phần tử tiếp theo trong một chuỗi: với văn bản là từ tiếp theo dựa trên ngữ cảnh ; với hình ảnh là pixel tiếp theo dựa trên tất cả pixel trước đó.
Phương pháp này tối ưu hóa khả năng tái tạo dữ liệu ở mức chi tiết bề mặt (surface-level detail), không phải ở mức cấu trúc ngữ nghĩa (semantic structure). Hệ quả là mô hình học cách "trông có vẻ đúng" hơn là "thực sự đúng". Đây chính là nguồn gốc của hiện tượng hallucination (ảo giác): mô hình tự tin tạo ra những thông tin sai lệch vì nó đang tối ưu hóa sự mượt mà của chuỗi văn bản, không phải tính xác thực của nội dung.
Ngoài vấn đề chất lượng, Autoregressive modeling còn đặt ra thách thức về tài nguyên tính toán. Để dự đoán từng token trong một câu trả lời dài, mô hình phải xử lý toàn bộ ngữ cảnh qua nhiều lớp Transformer, dẫn đến độ phức tạp tính toán theo độ dài chuỗi — một điểm nghẽn cổ chai nghiêm trọng khi triển khai ở quy mô lớn.
Triết Lý Của Yann LeCun: Từ "Vẹt Thống Kê" Đến "Autonomous Intelligence"
Yann LeCun, một trong những cha đẻ của Deep Learning và hiện là Chief AI Scientist tại Meta, đã nhiều lần chỉ trích mạnh mẽ hướng tiếp cận LLM hiện tại. Trong bài luận nổi tiếng năm 2022, "A Path Towards Autonomous Machine Intelligence", ông lập luận rằng LLM chỉ là những "stochastic parrots" (vẹt thống kê) tinh vi — chúng mô phỏng ngôn ngữ của trí tuệ mà không sở hữu nền tảng nhận thức thực sự.
Luận điểm trung tâm của LeCun xoay quanh khái niệm World Model — một biểu diễn nội tại của thế giới cho phép tác nhân AI:
Dự đoán hậu quả của hành động trước khi thực hiện chúng.
Lập kế hoạch theo mục tiêu dài hạn bằng cách mô phỏng các kịch bản khả dĩ.
Học nhanh từ ít ví dụ vì đã có nền tảng hiểu biết về thế giới vật lý.
Trẻ em con người làm được tất cả những điều này mà không cần đọc hàng nghìn tỷ từ. Một đứa trẻ 18 tháng tuổi hiểu rằng vật thể không biến mất khi bị che khuất (object permanence), buông tay thì vật thể cầm trong tay bị rới xuống đất, rằng nước chảy xuống dốc. Đây là common sense — kiến thức nền tảng về vật lý học trực giác mà não người hấp thụ thụ động từ việc quan sát và tương tác với thế giới, không cần nhãn (label) hay phần thưởng (reward) tường minh.
Để đạt được mức độ trí tuệ này, LeCun đề xuất rằng AI cần một kiến trúc học đặc trưng (representation learning architecture) hoàn toàn khác — không dự đoán trong không gian dữ liệu thô, mà dự đoán trong không gian ẩn (latent space). Đây chính là điểm khởi sinh của JEPA.
JEPA — viết tắt của Joint-Embedding Predictive Architecture — là một họ kiến trúc học biểu diễn (representation learning) được thiết kế để học các đặc trưng ngữ nghĩa trừu tượng từ dữ liệu chưa được gán nhãn.
Nguyên lý cốt lõi của JEPA có thể được phát biểu ngắn gọn:
Thay vì dự đoán dữ liệu gốc trong không gian quan sát, JEPA dự đoán biểu diễn trong không gian ẩn từ biểu diễn ngữ cảnh .
Điều này tạo ra một sự khác biệt triết học sâu sắc. Khi một mô hình Autoregressive tạo ra hình ảnh, nó phải "vẽ" từng pixel một — một nhiệm vụ đòi hỏi mô hình phải giữ lại (hay tái tạo) mọi chi tiết bề mặt, kể cả những chi tiết không liên quan đến ngữ nghĩa. Ngược lại, JEPA chỉ cần học cấu trúc ngữ nghĩa của dữ liệu — những đặc trưng trừu tượng, bất biến (invariant) trước các biến đổi không quan trọng như nhiễu, thay đổi màu sắc, hay biến dạng nhỏ.
Đây là lý do tại sao LeCun gọi JEPA là kiến trúc cho "energy-based world modeling": thay vì học phân phối xác suất trên toàn bộ không gian dữ liệu (rất tốn kém về mặt tính toán), JEPA học một hàm năng lượng thấp khi và tương thích về mặt ngữ nghĩa.
Kiến Trúc — "Bộ Não" Của JEPA
Kiến trúc JEPA, đặc biệt là phiên bản I-JEPA (Image JEPA) được công bố năm 2023, được xây dựng trên ba thành phần chính hoạt động phối hợp với nhau:
Context Encoder - là một neural network làm nhiệm vụ nhận vào phần quan sát được và encode chúng thành một biểu diễn embedding
Target Endcoder - là một neural network có cấu trúc hệt như Context Encoder nhận vào toàn bộ dữ liệu sau đó encode ra các biểu diễn embedding cho các phần bị che (masked regions) để huấn luyện
Predictor - là một neural network nhỏ, thường là một Transofrmer hẹp nhận vào các biểu diễn embedding của Context Encoder, cùng với thông tin encode vị trí (positional encoding) của các phần bị che và đoán thể hiện phần bị che.
Bạn có thể hiểu tóm tắt luồng train của network như sau:
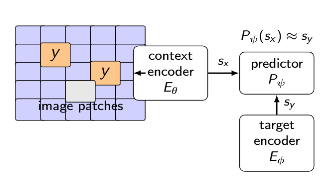
Đầu tiên chúng ta có một tấm ảnh, chúng ta chia tấm ảnh thành nhiều phần nhỏ (image patches)
Sau đó ta đem giấu / che một số phần (masked regions) - các phần y trên hình trên
Tiếp theo, ta đem từng phần chưa bị che đưa cho Context Encoder để nó encode thành các dạng embeddings cho context
Tương tự, chúng ta đem toàn bộ các phần qua Target Encoder (cả không che lẫn bị che) để encode thành dạng embeddings cho target
Cuối cùng ta train và dùng Predictor nhân vào toàn bộ context và thông tin vị trí của các phần bị che và cố gắng bắt Predictor đoán ra phần bị che đó là gì
Bảng ký hiệu
Trước khi đi vào chi tiết, bảng dưới đây tổng hợp toàn bộ ký hiệu toán học sử dụng:
Dữ liệu đầu vào quan sát được (phần không bị che - context)
Dữ liệu mục tiêu ( phần bị che - target cần dự đoán)
Tập tham số ( trọng số) của Context Encoder - được học qua gradient
Tập tham số của Target Encoder — được cập nhật bằng EMA, không qua gradient
Tập tham số của Predictor — được học qua gradient
Hàm Context Encoder với tham số : ánh xạ dữ liệu thành biểu diễn ẩn
Hàm Target Encoder với tham số : ánh xạ dữ liệu thành biểu diễn ẩn
Hàm Predictor với tham số : dự đoán biểu diễn target từ context
Biểu diễn ẩn (latent representation) của context ;
Biểu diễn ẩn của target theo Target Encoder;
Biểu diễn dự đoán của target — đầu ra của Predictor
Số chiều của không gian ẩn (latent dimension); thường
Hệ số momentum EMA; — kiểm soát tốc độ cập nhật
Thông tin vị trí (positional encoding) của vùng target trong ảnh/video
Số vùng target được chọn để dự đoán trong một lần huấn luyện
Context Encoder
Context Encoder là mạng nơ-ron nhận đầu vào là phần quan sát được (context) của dữ liệu và mã hóa nó thành một biểu diễn ẩn. Trong I-JEPA, đây là một Vision Transformer (ViT) nhận các patch ảnh chưa bị che (unmasked patches) và tạo ra embedding tương ứng.
Tham số của Context Encoder được tối ưu hóa trực tiếp thông qua gradient descent — đây là thành phần "học chủ động" của hệ thống.
Target Encoder
Target Encoder là thành phần tinh tế và quan trọng nhất trong kiến trúc JEPA. Về cấu trúc, nó giống hệt Context Encoder — cùng kiến trúc, cùng số tham số. Tuy nhiên, nó nhận đầu vào là toàn bộ dữ liệu (bao gồm cả phần bị che) và tạo ra target representations — những biểu diễn mà JEPA sẽ học cách dự đoán.
Điểm đặc biệt quan trọng của nó là tham số của Target Encoder không được cập nhật bằng gradient. Thay vào đó, nó được cập nhật theo cơ chế Exponential Moving Average (EMA) từ tham số của Context Encoder:
trong đó là hệ số momentum — một giá trị rất gần 1, nghĩa là Target Encoder thay đổi cực kỳ chậm. Đây chính là lý do Target Encoder được gọi là "người thầy thầm lặng": nó cung cấp một mục tiêu học tập ổn định (stable target) cho Predictor, tránh hiện tượng mục tiêu thay đổi quá nhanh gây ra sự huấn luyện bất ổn định. Có một điều mình muốn nhấn mạnh ở đây là không phải là chân lý, nó chỉ đóng vai trò là hệ quy chiếu. Trong học có giám sát (Supervised Learning), nhãn "Con mèo" là chân lý. Nhưng trong JEPA, bản thân (đầu ra của ) ban đầu chỉ là một đống số ngẫu nhiên vô nghĩa.
Nó "đúng" không phải vì nó phản ánh đúng khái niệm con mèo.
Nó "đúng" vì nó là một phép chiếu ổn định của dữ liệu thực .
phải "noi theo" không phải để học kiến thức từ , mà để đồng bộ hóa cách nhìn thế giới với .
Như vậy làm cách nào để "noi theo" ? Predictor sẽ tham gia để giải quyết vấn đề đó.
Predictor
Predictor là một mạng nơ-ron nhỏ (thường là Transformer hẹp) nhận đầu vào là biểu diễn ngữ cảnh từ Context Encoder cùng với thông tin vị trí (positional information) của các vùng bị che, và dự đoán biểu diễn của những vùng đó theo Target Encoder:
Mục tiêu là tối thiểu hóa khoảng cách giữa dự đoán và target :
Predictor cũng được huấn luyện theo back propagation. Khi hàm Loss được tính toán dựa trên sự sai lệch giữa (dự đoán) và (mục tiêu), đạo hàm sẽ được tính và đẩy ngược về theo hai nhánh:
Nhánh 1: Đẩy vào Predictor để cập nhật . Mục tiêu để làm cho Predictor "thông minh" hơn trong việc suy luận từ sang .
Nhánh 2: Tiếp tục đẩy xuyên qua Predictor để vào Context Encoder () để cập nhật . Mục tiêu để làm cho Context Encoder biết cách trích xuất những đặc trưng "có giá trị dự báo cao" từ dữ liệu thô .
Hãy tưởng tượng Predictor như một "người thầy chấm bài":
Nếu đưa ra một vector hời hợt, Predictor sẽ không tài nào đoán được . Loss sẽ cao.
Để làm hài lòng Predictor, buộc phải vắt kiệt thông tin từ để tạo ra một chất lượng nhất.
Cơ Chế Masking: Học "Toàn Thể" Từ "Một Phần"
Masking (che phủ) là chiến lược huấn luyện trung tâm của JEPA, lấy cảm hứng từ Masked Autoencoder (MAE) nhưng với triết lý khác biệt căn bản. Trong I-JEPA, mỗi ảnh đầu vào được chia thành các patch nhỏ. Quá trình masking diễn ra theo hai bước:
Target masking: Chọn ngẫu nhiên vùng mục tiêu — đây là những vùng mà mô hình cần dự đoán biểu diễn. Các vùng này được chọn với tỷ lệ che cao (thường 85-95%), và quan trọng là chúng được chọn theo block masking — che các vùng hình chữ nhật liên tục thay vì các patch ngẫu nhiên rời rạc.
Context masking: Từ phần còn lại (sau khi đã loại bỏ target), chọn một tập con nhỏ hơn làm ngữ cảnh đầu vào cho Context Encoder. Điều này đảm bảo ngữ cảnh và target không chồng lấn, buộc mô hình phải suy luận về target từ ngữ cảnh hạn chế.
Chiến lược block masking có ý nghĩa sâu xa: nó tạo ra nhiệm vụ dự đoán ngữ nghĩa (semantic prediction) thay vì nội suy cục bộ (local interpolation). Khi một vùng lớn bị che, mô hình không thể chỉ dựa vào gradient màu sắc từ các pixel lân cận — nó phải hiểu cấu trúc đối tượng để đoán được nội dung của vùng bị che.
Sự Khác Biệt Với Autoencoders:
Để hiểu rõ điểm độc đáo của JEPA, hãy so sánh nó với Masked Autoencoder (MAE) — một kiến trúc cũng sử dụng masking nhưng theo cách tiếp cận Autoregressive.
Tiêu Chí | Masked Auto Encoder (MAE) | JEPA |
|---|---|---|
Mục tiêu dự đoán | Pixel gốc trong không gian ảnh | | Biểu diễn ẩn trong latent space |
Không gian dự đoán |
| với |
Loại thông tin học | Chi tiết bề mặt + cấu trúc | Chỉ cấu trúc ngữ nghĩa |
Rủi ro collapse | Thấp (target cố định là pixel) | Cao (cần cơ chế chống collapse) |
Hiệu quả tính toán | Kém hơn do decoder phức tạp | Tốt hơn do predictor nhỏ |
Sự khác biệt cốt lõi nằm ở bản chất của mục tiêu học. MAE buộc mô hình phải lưu giữ và tái tạo mọi chi tiết của ảnh gốc — điều này vừa tốn tài nguyên vừa khuyến khích mô hình học những đặc trưng không liên quan đến ngữ nghĩa (texture, noise, lighting artifacts). JEPA, bằng cách dự đoán trong latent space, cho phép mô hình trừu tượng hóa (abstract away) những chi tiết không quan trọng và tập trung vào cấu trúc ngữ nghĩa cấp cao.
LeCun minh họa điều này bằng một ví dụ trực giác: khi bạn nhìn thấy một con mèo đằng sau một cái cây và cái cây di chuyển sang bên, bạn không cần "vẽ" lại con mèo trong đầu để hiểu nó vẫn ở đó — bạn chỉ cần duy trì biểu diễn ngữ nghĩa của "con mèo ở vị trí X". JEPA mô phỏng chính xác quá trình nhận thức này.
Ý tưởng cốt lõi của việc huấn luyện
Tóm lại, ý tưởng của Yan Lecun là:
(Người quan sát cục bộ): Chỉ được nhìn một phần thế giới (). Nó đang cố gắng xây dựng một "thế giới quan" từ những mảnh ghép vụn vặt.
(Người nắm giữ bối cảnh): Nó được nhìn thấy toàn bộ hoặc phần quan trọng khác của thế giới (). Nhưng nó không "dạy" theo kiểu đưa đáp án, nó chỉ đứng đó như một tiêu chuẩn về sự hiểu biết.
Predictor (Bài kiểm tra tư duy): Đây là điểm mấu chốt. Nó không bắt phải giống hệt . Nó bắt phải suy luận: "Với những gì bạn thấy ở , bạn có đoán được cách mà nhìn thấy ở không?". Đây là sự chuyển đổi từ nhìn sang hiểu.
Sự tích lũy của : Đây là ý hay nhất, là nơi tích lũy "cách nhìn tốt nhất" của thông qua EMA. Nó gạn lọc những gì ổn định nhất để tạo ra một khái niệm rõ ràng hơn (concepts) về thế giới, giúp bài kiểm tra (của Predictor) sau này trở nên có ý nghĩa hơn.
Nền tảng toán học
Trong các hệ thống học tự giám sát không sử dụng mẫu âm (Non-contrastive SSL), thách thức lớn nhất không phải là học cái gì, mà là chống lại xu hướng sụp đổ (collapse) của mạng thần kinh. Để hiểu JEPA, ta phải hiểu cách nó điều phối các lực toán học để định hình không gian ẩn.
Hàm Loss Invariance: Ép Dự Đoán Khớp Với Thực Tế
Thành phần đầu tiên và trực tiếp nhất của hàm loss trong JEPA là Invariance Loss , đo khoảng cách giữa biểu diễn được dự đoán và biểu diễn mục tiêu. Đây là "lực hút" ép dự đoán phải tiến về gần mục tiêu .
Trong đó:
: Số lượng các khối dữ liệu mục tiêu (target blocks).
: Vector đặc trưng dự đoán bởi mạng Predictor ().
: Vector đặc trưng được trích xuất bởi mạng Target Encoder ().
: Toán tử Stop-Gradient.
Toán tử Stop-Gradient là một chỉ thị trong quá trình tính toán đồ thị đạo hàm. Khi áp dụng vào một biến số (trong trường hợp này là ), hệ thống sẽ:
Giữ nguyên giá trị của biến số đó trong quá trình lan truyền xuôi (Forward pass) để tính toán giá trị hàm mất mát.
Ngắt hoàn toàn việc tính toán và truyền đạo hàm qua biến số đó trong quá trình lan truyền ngược (Backpropagation).
Về mặt kỹ thuật, điều này có nghĩa là bộ tham số của mạng Target Encoder sẽ không nhận được bất kỳ tín hiệu cập nhật nào trực tiếp từ hàm mất mát này. Việc đưa toán tử vào công thức là bắt buộc vì các lý do sau:
Ngăn chặn sự sụp đổ thông tin (Collapse): Nếu không có , thuật toán tối ưu hóa (Gradient Descent) sẽ tìm cách giảm hàm mất mát bằng cách thay đổi đồng thời cả mạng Online () và mạng Target (). Cách nhanh nhất để giảm khoảng cách giữa hai đại lượng này là ép cả hai mạng cùng trả về một giá trị hằng số (ví dụ: vector toàn số 0). Khi đó, hàm mất mát sẽ bằng 0 nhưng mô hình không học được bất kỳ thông tin hữu ích nào từ dữ liệu.
Xác lập vai trò của mạng Target Encoder: ép mạng Target Encoder trở thành một "hệ quy chiếu tĩnh" trong mỗi bước cập nhật. Nó buộc mạng Online và Predictor phải tự điều chỉnh bộ tham số của mình để khớp với mục tiêu, thay vì mạng Target tự điều chỉnh để "chiều theo" mạng Online.
Đảm bảo tính hợp lệ của cơ chế EMA: Trong JEPA, mạng Target Encoder được thiết kế để cập nhật chậm thông qua cơ chế Trung bình trượt lũy thừa (EMA) từ mạng Online. Toán tử đảm bảo rằng EMA là con đường duy nhất để mạng Target tiến hóa, duy trì sự ổn định cần thiết cho quá trình huấn luyện.
Tuy nhiên, chỉ có là chưa đủ — nó dẫn đến một vấn đề nguy hiểm gọi là representational collapse.
VICReg — Chống Lại Sự Sụp Đổ Biểu Diễn
Representational collapse (sụp đổ biểu diễn - do lực hút của Invariance) là hiện tượng mô hình học cách giảm thiểu loss một cách tầm thường bằng cách mapping mọi đầu vào đến cùng một điểm trong latent space — một "giải pháp" không có giá trị biểu diễn nào. Nếu với mọi , thì nhưng mô hình không học được gì cả.
Để đối trọng với sự sụp đổ biểu diễn, Yann LeCun và các cộng sự tại Meta đã giới thiệu VICReg (Variance-Invariance-Covariance Regularization). Đây không chỉ là các hàm phạt, mà là một hệ thống tối đa hóa lượng tin. VICReg (Variance-Invariance-Covariance Regularization), được đề xuất bởi Bardes et al. (2022) tại Meta AI, cung cấp giải pháp toán học cho vấn đề này thông qua hai thành phần regularization bổ sung.
Variance Loss — Duy Trì Năng Lượng Thông Tin
Variance Loss đảm bảo rằng mỗi chiều của biểu diễn ẩn duy trì đủ phương sai — ngăn chặn việc các chiều co lại về 0:
Trong đó:
là ma trận biểu diễn ẩn (ma trận mã nhúng - Embeddings), kích thước , với là số lượng mẫu trong một batch và là số chiều của không gian ẩn.
là cột thứ đại diện cho tất cả giá trị của chiều thứ tính trên toàn bộ các mẫu trong batch đó.
Hàm này ép mỗi chiều của vector mã nhúng phải duy trì một độ biến thiên tối thiểu.
Cơ chế Hinge Loss: Khi độ lệch chuẩn lớn hơn ngưỡng (thường là 1), Loss bằng 0. Khi , một lực đẩy xuất hiện ép các giá trị phải giãn ra.
Về mặt trực giác đảm bảo rằng mỗi "sensor" (chiều) trong mã nhúng luôn ở trạng thái hoạt động (active). Từ góc nhìn Lý thuyết thông tin, việc ép phương sai cao tương đương với việc duy trì mức năng lượng tối thiểu cho tín hiệu, ngăn chặn việc các neuron bị "chết" hoặc trở thành hằng số.
Covariance Loss — Chống sụp đổ chiều (Dimensional Redundancy)
Covariance Loss tấn công một vấn đề khác: ngay cả khi mỗi chiều có phương sai đủ lớn, chúng có thể tương quan cao với nhau, nghĩa là các chiều chứa thông tin trùng lặp (redundant information). Điều này làm giảm hiệu quả của biểu diễn:
Trong đó:
là ma trận hiệp phương sai (covariance matrix) của batch biểu diễn :
: Số chiều (dimension) của không gian ẩn (latent space).
: Chỉ số đại diện cho các chiều khác nhau trong vector mã nhúng ().
: Phần tử nằm ở hàng và cột của ma trận hiệp phương sai, đại diện cho mức độ tương quan giữa chiều thứ và chiều thứ .
: Phép tổng thực hiện trên tất cả các phần tử ngoài đường chéo chính (off-diagonal). Việc bình phương các phần tử này () đảm bảo các giá trị âm và dương đều bị phạt như nhau khi chúng khác 0.
Vector mã nhúng của mẫu thứ trong batch
: Vector trung bình của toàn bộ batch ().
penalize các off-diagonal entries của — tức là các hiệp phương sai giữa các cặp chiều khác nhau. Bằng cách ép gần với ma trận đơn vị (diagonal matrix với các phần tử diagonal bằng nhau), VICReg khuyến khích các chiều biểu diễn trở nên thống kê độc lập với nhau, điều này tương đương với việc tối đa hóa entropy của phân phối biểu diễn.
Từ góc nhìn lý thuyết thông tin, đây là nguyên lý Minimum Redundancy — Maximum Relevance (mRMR): một biểu diễn tốt nên tối đa hóa thông tin về đầu vào trong khi tối thiểu hóa sự trùng lặp giữa các chiều.
Hàm loss tổng hợp của VICReg:
với là các siêu tham số cân bằng. Trong thực tế, giá trị thường được sử dụng, phản ánh tầm quan trọng tương đối của invariance và variance so với covariance.
Demo
Demo dưới đây nhằm giúp các bạn hiểu hơn về cách JEPA hoạt động, tuy nhiên phải nói là training JEPA quá khó nên không phải lúc nào thuật toán training cũng hội tụ đẹp, cũng có thể là do mình đang dùng các cấu trúc đơn giản để mô tả cho predictor và các encoder nên kết quả không ra tốt như mong muốn... sẽ update trong tương lai ✨
Mối Liên Hệ Với Actor-Critic Trong Reinforcement Learning
Cơ chế Target Encoder với EMA trong JEPA có sự tương đồng đáng chú ý với kiến trúc Target Network trong Deep Q-Network (DQN) và các thuật toán Actor-Critic trong Reinforcement Learning (RL).
Trong DQN (Mnih et al., 2015), mạng Q-value chính được huấn luyện để tối thiểu hóa TD-error:
Ở đây, là Target Network — một bản sao "đóng băng" của được cập nhật định kỳ (hoặc theo EMA). Nếu cả hai mạng cùng được cập nhật đồng thời, mục tiêu huấn luyện (bootstrapped TD-target) sẽ thay đổi liên tục cùng với mô hình, tạo ra "chasing a moving target" — vòng lặp phản hồi bất ổn định.
Thanh phần | RL (DQN/Actor-Critic) | JEPA |
|---|---|---|
Mạng học chủ động | Online Q-network | Context Encoder + Predictor |
Mạng mục tiêu | Target Network | Target Encoder |
Cơ chế cập nhật mục tiêu | Periodic copy hoặc EMA | EMA với |
Mục đích | Ổn định TD-Target | Ổn định representation target |
Nguồn tín hiệu học | Reward từ environment | Cấu trúc dữ liệu (self-supervised) |
Sự tương đồng này không phải ngẫu nhiên. Cả hai kiến trúc đều giải quyết cùng một vấn đề cơ bản: làm thế nào để học từ một mục tiêu (target) khi bản thân mục tiêu đó cũng đang thay đổi theo quá trình học? Câu trả lời trong cả hai trường hợp là: làm chậm quá trình thay đổi của mục tiêu xuống để tạo ra một "ground truth" tạm thời ổn định.
Từ góc nhìn lý thuyết điều khiển (control theory), đây là bài toán two-timescale optimization: một quá trình tối ưu hóa nhanh (Context Encoder + Predictor) và một quá trình cập nhật chậm (Target Encoder), trong đó quá trình nhanh hội tụ đến trạng thái cân bằng trước khi quá trình chậm thay đổi đáng kể.
JEPA trong thực tế
I-JEPA: Hiểu Cấu Trúc Vật Thể Không Cần Nhãn
I-JEPA (Image JEPA), được Meta AI công bố vào tháng 6 năm 2023, là minh chứng đầu tiên và thuyết phục nhất về hiệu quả của kiến trúc JEPA trong lĩnh vực thị giác máy tính.
Được huấn luyện trên ImageNet-1K (1.28M ảnh) với kiến trúc ViT-H/14 (backbone ViT-Huge với patch size 14), I-JEPA đạt được những kết quả đáng chú ý:
- Linear probing accuracy: 77.3% trên ImageNet, so với MAE đạt 75.3% với cùng điều kiện huấn luyện.
- Data efficiency: Đạt kết quả tốt hơn MAE với ít epoch huấn luyện hơn đáng kể (ViT-H/16 sau 300 epochs so với 1600 epochs của MAE).
- Transfer learning: Vượt trội trên các tác vụ downstream như phát hiện vật thể (object detection) và phân đoạn ngữ nghĩa (semantic segmentation).
Điều quan trọng hơn các con số là bản chất của đặc trưng (feature) mà I-JEPA học. Khi phân tích các biểu diễn qua nearest-neighbor search, I-JEPA tạo ra các cluster dựa trên ngữ nghĩa đối tượng (object semantics) và cấu trúc hình học (geometric structure) — không phải dựa trên đặc trưng texture hay màu sắc bề mặt như các phương pháp Autoregressive. Điều này phản ánh rằng I-JEPA đang học "hình dạng và bản chất của vật thể là gì", không phải "vật thể trông như thế nào trong bức ảnh cụ thể này".
V-JEPA: Học Quy Luật Vật Lý Của Thế Giới Qua Video
V-JEPA (Video JEPA), được Meta AI công bố đầu năm 2024, mở rộng nguyên lý JEPA sang lĩnh vực video — đưa JEPA đến gần hơn với mục tiêu xây dựng World Model của LeCun.
V-JEPA hoạt động trên cơ sở tương tự I-JEPA nhưng với không gian-thời gian (spatiotemporal): thay vì che và dự đoán các patch ảnh 2D, V-JEPA che và dự đoán các tube video 3D — các khối không-thời-gian chứa một vùng không gian nhất định trong nhiều frame liên tiếp.
Điều đặc biệt về V-JEPA là khả năng nắm bắt quy luật vật lý học trực giác (intuitive physics) mà không cần bất kỳ nhãn hay chú thích nào:
Chuyển động và quán tính: V-JEPA học rằng vật thể không dịch chuyển đột ngột mà chuyển động liên tục theo quỹ đạo vật lý.
Lực hấp dẫn: Trong các video vật thể rơi, V-JEPA xây dựng biểu diễn phản ánh gia tốc đều, không chỉ vận tốc tức thời.
Tương tác vật thể: Va chạm, xếp chồng, và các tương tác cơ học khác được mã hóa vào biểu diễn mà không cần mô phỏng vật lý tường minh.
Cơ chế này hoạt động vì nhiệm vụ dự đoán trong latent space tự nhiên buộc mô hình phải tìm kiếm các invariant có tính dự đoán cao — và trong thế giới vật lý, các invariant đó chính là các quy luật vật lý. Một mô hình phải dự đoán biểu diễn của frame thứ từ frames đến sẽ phải học rằng "vật thể đang chuyển động với vận tốc sẽ ở vị trí sau frame" — đây chính là định luật chuyển động Newton.
Ứng Dụng: Robotics, Xe Tự Lái, Và Lập Kế Hoạch
Khả năng xây dựng World Model của JEPA mở ra những ứng dụng thực tiễn quan trọng trong các lĩnh vực đòi hỏi hiểu biết về vật lý thế giới thực:
Robotics và Điều Khiển Vật Lý: Robot cần mô hình thế giới để lập kế hoạch chuỗi hành động. Thay vì học policy trực tiếp (behavioral cloning) — vốn fragile trước các tình huống ngoài phân phối huấn luyện — robot được trang bị JEPA-based World Model có thể mô phỏng hậu quả của các hành động trong latent space trước khi thực thi, cho phép lập kế hoạch (planning) theo kiểu Model Predictive Control (MPC).
Xe Tự Lái: Hệ thống tự lái cần hiểu chuyển động của phương tiện khác, người đi bộ, và các đối tượng động. V-JEPA cung cấp biểu diễn ngữ nghĩa của chuyển động với chi phí tính toán thấp hơn đáng kể so với các mô hình xử lý từng pixel video.
Long-Horizon Planning: Một trong những thách thức lớn nhất của AI là lập kế hoạch dài hạn — chuỗi quyết định trải dài qua nhiều bước thời gian. JEPA-based World Model cho phép mô phỏng nhanh trong latent space, kiểm tra nhiều kịch bản hành động mà không cần thực thi thực tế — một năng lực thiết yếu cho các tác vụ như điều hướng robot trong môi trường phức tạp hay lập kế hoạch chiến lược trong game.
JEPA Có Thay Thế Transformer?
Daniel Kahneman, trong cuốn "Thinking, Fast and Slow" (2011), phân chia tư duy con người thành hai hệ thống:
System 1: Phản xạ nhanh, tự động, dựa trên pattern recognition và heuristics tích lũy từ kinh nghiệm.
System 2: Tư duy chậm, có ý thức, dựa trên logic và suy luận có chủ đích.
Khung này cung cấp một phép so sánh sâu sắc cho vị trí của LLM và JEPA trong hệ sinh thái AI:
LLM là System 1 của AI: Chúng rất nhanh trong việc tạo ra phản hồi phù hợp ngữ cảnh dựa trên pattern matching từ dữ liệu huấn luyện khổng lồ. Tuy nhiên, chúng thiếu khả năng suy luận có hệ thống về trạng thái thế giới — một đặc tính cơ bản của System 2. Khi gặp bài toán yêu cầu lập luận nhiều bước có cấu trúc (multi-step structured reasoning), LLM thường "đi tắt" thông qua pattern matching thay vì thực hiện suy luận thực sự.
JEPA là nền tảng cho System 2 của AI: Bằng cách xây dựng World Model trong latent space, JEPA cung cấp cơ sở hạ tầng nhận thức cho việc lập kế hoạch, suy luận nhân quả (causal reasoning), và tưởng tượng phản thực (counterfactual reasoning) — tất cả đều là đặc trưng của System 2.
Tuy nhiên, đây không phải là cuộc cạnh tranh zero-sum. Kiến trúc AI thực sự mạnh mẽ cần tích hợp cả hai: System 1 (LLM-like fast response) để xử lý ngôn ngữ tự nhiên và giao tiếp, và System 2 (JEPA-like world modeling) để lập kế hoạch và lý luận về thế giới vật lý. LeCun đề xuất kiến trúc tổng thể "Cognitive Architecture for Autonomous AI" trong đó JEPA đóng vai trò là World Model module, được điều phối bởi một Cost/Objective module và Perception/Action module.
Lộ Trình Tới AGI: JEPA Và Bài Toán Common Sense
Common sense — lẽ thường — là khả năng suy luận chính xác về thế giới dựa trên kiến thức nền tảng ngầm định (implicit background knowledge). Đây là thứ mà con người có một cách tự nhiên nhưng AI hiện tại thiếu một cách đáng ngạc nhiên.
Ví dụ: hỏi LLM "Nếu tôi đặt bát nước trong tủ lạnh 30 phút, điều gì xảy ra?" — mô hình sẽ trả lời đúng. Nhưng hỏi "Nếu tôi đặt bát nước trong tủ lạnh và tủ lạnh đang cháy, điều gì xảy ra?" — mô hình có thể cho câu trả lời kỳ lạ vì nó đang thực hiện pattern matching thay vì lý luận nhân quả.
JEPA tiếp cận bài toán common sense từ hướng trực giác vật lý (physical intuition): thay vì cố gắng encode common sense như một tập luật (rule-based approach) hay học nó từ văn bản (LLM approach), JEPA học common sense từ quan sát trực tiếp thế giới vật lý — cách mà trẻ em hấp thụ nó. Quá trình học của V-JEPA từ video chính là quá trình tích lũy "vật lý học ngây thơ" (naïve physics) vào cấu trúc biểu diễn.
Về lộ trình dài hạn, LeCun và cộng sự phác thảo một hệ thống phân cấp (hierarchy) của World Models, từ:
Reflexive level: Phản xạ cơ bản, không cần lập kế hoạch.
Reactive level: World model đơn giản, lập kế hoạch ngắn hạn.
Deliberative level: World model chi tiết, lập kế hoạch dài hạn.
Cognitive level: Meta-learning, học cách học, khái quát hóa.
JEPA hiện tại hoạt động chủ yếu ở các level 2-3. Mở rộng JEPA để xử lý biểu diễn đa phương thức (multi-modal: ảnh, video, âm thanh, ngôn ngữ) trong một World Model thống nhất là một trong những hướng nghiên cứu tích cực nhất trong cộng đồng Meta AI Research.
Kết Luận
JEPA không phải là câu trả lời cho mọi thách thức của AI — và LeCun cũng không khẳng định như vậy. Đây là một triết lý học biểu diễn (representation learning philosophy): dự đoán trong không gian ẩn, không phải không gian dữ liệu thô. Triết lý này dẫn đến các kiến trúc học được đặc trưng ngữ nghĩa hiệu quả hơn, ổn định hơn, và về mặt lý thuyết gần hơn với cách não người xử lý thông tin.
Câu hỏi không phải là "JEPA có thay thế Transformer không?" mà là "JEPA và Transformer sẽ bổ sung cho nhau như thế nào trong các kiến trúc AI thế hệ tiếp theo?". Khi LLM tiếp tục đảm nhận vai trò giao tiếp ngôn ngữ, JEPA — hay các phiên bản kế thừa của nó — có thể trở thành nhân của World Model module trong các hệ thống AI thực sự có khả năng lý luận, lập kế hoạch, và hành động trong thế giới vật lý.
Con đường từ "stochastic parrot" đến "autonomous intelligence" còn dài, nhưng JEPA đang chỉ ra một hướng đi đầy hứa hẹn.
Tài Liệu Tham Khảo
LeCun, Y. (2022). A Path Towards Autonomous Machine Intelligence. OpenReview.
Assran, M., Duval, Q., Misra, I., et al. (2023). Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture. CVPR 2023.
Bardes, A., Ponce, J., & LeCun, Y. (2022). VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning. ICLR 2022.
Bardes, A., Garrido, Q., Ponce, J., et al. (2024). V-JEPA: Latent Video Prediction for Visual Representation Learning. Meta AI Research.
Grill, J.-B., Strub, F., Altché, F., et al. (2020). Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. NeurIPS 2020.
He, K., Chen, X., Xie, S., et al. (2022). Masked Autoencoders Are Scalable Vision Learners. CVPR 2022.
Mnih, V., Kavukcuoglu, K., Silver, D., et al. (2015). Human-level control through deep reinforcement learning. Nature.
Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux.
More from AI & ML
- RL - Từ TD-Learning đến Q-Learning
- RL - Phương pháp Actor Critic
- Reinforcement Learning - Học theo Chính Sách (Policy Gradient)
- Reinforcement Learning - Bài mở đầu
- Multi-Armed Bandits: Từ Greedy đến UCB rồi đến Exp3
- Cơ bản về ANN - Artificial Neural Network
- Aritificial Neural Network: Bản chất Xác suất phía sau Bài toán Hồi quy
- NEAT (NeuroEvolution of Augmenting Topologies)- Nhiệm vụ hạ cánh tàu vũ trụ
- Q-Learning căn bản - Nhiệm vụ hạ cánh tàu vũ trụ
- Singular Value Decomposition (SVD) Demo
- Thuật toán K-Means demo
Comments
No comments yet. Be the first to comment!