RL - Phương pháp Actor Critic
Trong các bài viết trước, chúng ta đã đi qua những viên gạch nền móng đầu tiên của Reinforcement Learning. Từ việc định hình bài toán bằng phương trình Bellman, chứng minh sự hội tụ bằng ánh xạ co (Contraction Mapping) ở bài 1, cho đến việc hiện thực hóa lý thuyết thành thuật toán cụ thể như Q-Learning và DQN dựa trên nền tảng Học sai biệt thời gian (Temporal Difference Learning) ở bài 2.
Tất cả các phương pháp đó đều có một điểm chung: Chúng thuộc trường phái Value-based (Dựa trên giá trị). Tư tưởng cốt lõi của Value-based là cố gắng học một hàm giá trị thật chuẩn xác (như hàm ), rồi từ đó suy ra hành động một cách gián tiếp bằng chiến lược tham lam (Greedy) — nghĩa là trạng thái nào có điểm cao nhất thì ta chọn.
Một hướng tiếp khác thay vì tiếp cận trên value-based đã ra đời: Policy-based mà đại diện là thuật toán Policy Gradient ở bài 3. Mặc dù Policy Gradient giải quyết được bài toán hành động liên tục và chính sách ngẫu nhiên, nó lại mang một điểm yếu chí mạng khác: Phương sai quá lớn (High Variance), khiến mô hình học rất chậm và không ổn định.
Hôm nay chúng ta cùng nhau tìm hiểu một phương pháp mới là Actor-Critic. Đây là một sự kết hợp hài hòa và tinh tế giữa hai trường phái tưởng chừng như đối lập: Value-based và Policy-based.
Review Policy Gradient
Trong Policy Gradient, mục tiêu cốt lõi của chúng ta là tìm bộ tham số chính sách sao cho tối đa hóa phần thưởng tích lũy kỳ vọng. Hàm mục tiêu được định nghĩa là:
Trong đó là tổng phần thưởng chiết khấu thu được từ thời điểm . Để tối ưu hóa hàm mục tiêu này, Định lý Gradient chính sách (Policy Gradient Theorem) chỉ ra hướng cập nhật tăng gradient cho như sau:
Khái niệm Baseline và Chứng minh tính không chệch (Unbiasedness)
Việc sử dụng trực tiếp giá trị phần thưởng thực tế dẫn đến phương sai (variance) rất lớn trong việc ước lượng gradient. Nhằm giảm bớt phương sai, chúng ta trừ đi một hàm baseline chỉ phụ thuộc vào trạng thái hiện tại mà không phụ thuộc vào hành động. Gradient sửa đổi có dạng:
Chứng minh chi tiết toán học: (Mình đã chứng minh ở bài trước rồi, tuy nhiên mình vẫn sẽ chứng minh lại ở đây để đọc cho tiện) Việc trừ đi baseline hoàn toàn không làm thay đổi hướng góc của gradient (không gây chệch). Chúng ta chứng minh giá trị kỳ vọng của thành phần chứa baseline bằng 0:
Bước 1: Khai triển kỳ vọng theo phân phối trạng thái và phân phối hành động :
Bước 2: Đưa Baseline ra ngoài vì độc lập với hành động :
Bước 3: Sử dụng mẹo Đạo hàm Log (Log-Derivative Trick) với công thức :
Biểu thức trong dấu ngoặc vuông trở thành:
Bước 4: Tráo đổi tổng và gradient. Vì tổng xác suất của tất cả các hành động trong một trạng thái luôn bằng 1 ():
Kết luận: Do thành phần bên trong bằng 0, toàn bộ kỳ vọng của số hạng baseline bằng 0:
Từ đó khẳng định việc thêm baseline giúp giảm phương sai hiệu quả mà không làm sai lệch kết quả tối ưu.
Hàm Advantage (Hàm Lợi Thế) và Ý tưởng từ TD-Learning
phương pháp Monte Carlo thuần túy sử dụng toàn bộ chuỗi phần thưởng có nhược điểm lớn:
Phương sai cao: Do tích lũy sự ngẫu nhiên từ mọi hành động và trạng thái tiếp theo trong tương lai.
Ràng buộc theo tập (Episodic): Chỉ có thể cập nhật trọng số sau khi một tập (episode) đã kết thúc hoàn toàn.
Kém hiệu quả: Không áp dụng mượt mà cho các tác vụ liên tục (continuous) hoặc có chu kỳ dài.
Giải pháp cải tiến là chuyển dịch sang Học sai biệt thời gian (Temporal Difference - TD Learning) thông qua 3 định nghĩa hàm giá trị:
Hàm Giá trị trạng thái : Kỳ vọng phần thưởng khi bắt đầu từ trạng thái .
Hàm Giá trị hành động : Kỳ vọng phần thưởng khi đứng ở trạng thái và thực hiện hành động .
Hàm Lợi thế : Đo lường mức độ hiệu quả của một hành động cụ thể so với mức trung bình của trạng thái đó:
Khi chọn hàm baseline tối ưu , thành phần có thể thay thế bằng hàm Lợi thế . Hàm mục tiêu cập nhật chính sách mới trở thành:
Về mặt lý thuyết, để xác định được giá trị lợi thế tại mỗi bước, hệ thống bắt buộc phải ước lượng hoặc tính toán đồng thời hai đại lượng riêng biệt: Giá trị của cặp trạng thái - hành động và Giá trị trung bình của trạng thái . Tuy nhiên, việc phải duy trì hai bộ ước lượng song song—bù lại—sẽ làm phức tạp hóa bài toán tính toán (cho dù ta lưu trữ dạng bảng (Tabular) hay xấp xỉ bằng hàm số/mạng thần kinh). Để tối ưu hóa cấu trúc này, chúng ta tận dụng bản chất đệ quy của môi trường thông qua Phương trình Bellman 1 bước.
Chứng minh toán học triệt tiêu hàm để giảm số lượng đại lượng cần ước lượng
Theo định nghĩa, hàm giá trị hành động chính là kỳ vọng của phần thưởng tức thời cộng với giá trị chiết khấu của trạng thái kế tiếp:
Bằng cách sử dụng giá trị mẫu thực tế tại mỗi bước để xấp xỉ (stochastic approximation), ta có thể biểu diễn gián tiếp thông qua :
Khi thế biểu thức xấp xỉ này vào công thức gốc của hàm Lợi thế , một phép biến đổi toán học xuất hiện:
Biểu thức rút gọn này chính là Sai số sai biệt thời gian (TD Error), ký hiệu là :
Nhờ phép biến đổi toán học này, hàm Lợi thế giờ đây đã được quy đổi hoàn toàn về một hàm duy nhất là Hàm giá trị trạng thái thay vì phải tìm cách tính toán/ước lượng cả hai hàm số và .
Thuật toán Actor-Critic
Bây giờ, bài toán được tinh giản chỉ còn cấu thành từ Chính sách chọn hành động () và Hàm giá trị trạng thái ()—mô hình Actor-Critic chính thức được khai sinh như một sự phân rã nhiệm vụ tự nhiên và tường minh. Mô hình này chia hệ thống học tăng cường làm hai thành phần chính tương tác đồng thời với nhau:
Actor (Bộ hành động / "Vận động viên"):
Bản chất: Chính là đại diện cho chính sách được tham số hóa bởi bộ trọng số . Thông thường, chúng ta dùng một neural network để biểu diễn cho Actor với các giá trị chính là bộ trọng số của mạng.
Nhiệm vụ: Nhìn vào trạng thái hiện tại của môi trường để đưa ra quyết định chọn hành động tối ưu nhất nhằm thu về nhiều phần thưởng.
Critic (Bộ phê bình / "Huấn luyện viên"):
Bản chất: Chính là bộ ước lượng cho hàm giá trị trạng thái mà ta vừa rút gọn được ở trên. Tùy theo độ phức tạp của bài toán, Critic có thể là một bảng tra cứu (Tabular -table) hoặc một hàm xấp xỉ phức tạp (như Neural Network với tham số ).
Nhiệm vụ: Critic không trực tiếp sinh ra hành động. Nó chỉ đóng vai trò là một người đánh giá nội tại, quan sát trạng thái , nhận phần thưởng thực tế và trạng thái kế tiếp để tính toán ra thước đo TD Error ().
Actor và Critic tạo thành một vòng lặp phản hồi khép kín:
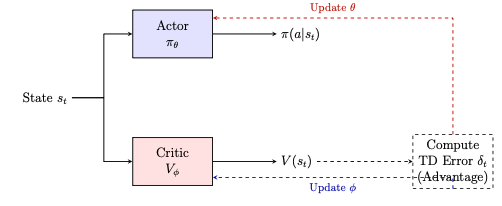
Actor tương tác với môi trường để sinh ra dữ liệu mẫu.
Critic đứng sau quan sát dữ liệu mẫu đó, tính ra sai số . Tín hiệu này đóng vai trò như một "lời phê bình": Nếu , hành động Actor vừa chọn tốt hơn mong đợi; nếu , hành động đó tệ hơn mong đợi.
Tín hiệu của Critic sẽ được gửi lại để làm kim chỉ nam điều chỉnh cho cả hai: giúp Actor nâng cao/hạ thấp xác suất chọn lại hành động đó, và giúp chính Critic tinh chỉnh khả năng dự đoán giá trị của mình ngày một chính xác hơn.
Trong thực tế, chúng ta dùng 2 mạng neural network để biểu diễn cho Actor và Critic và chúng ta sẽ huấn luyện 2 mạng này sao cho chúng có thể tự điểu chỉnh trọng số để làm cho agent ngày càng thông minh hơn.
Cập nhật cho Critic ()
Mục tiêu toán học của mạng Critic là ước lượng giá trị sao cho càng ngày càng sát với giá trị thực tế của môi trường. Do đó, bài toán học của Critic bản chất là một bài toán Học có giám sát (Supervised Learning), với mục tiêu (Target) là giá trị Bootstrapping: .
Hàm mất mát (Loss function) của Critic được định nghĩa bằng Bình phương sai số trung bình (MSE Loss):
Để tối thiểu hóa hàm mất mát này, chúng ta sử dụng phương pháp Hạ gradient (Gradient Descent). Khai triển đạo hàm của theo bộ tham số bằng quy tắc chuỗi (Chain Rule):
Lưu ý: Trong kỹ thuật Bootstrapping tiêu chuẩn (như Semi-gradient TD), khi tính đạo hàm đối với trạng thái hiện tại , thành phần mục tiêu được coi là hằng số cố định (nghĩa là ta không lan truyền ngược gradient qua ).
Quy tắc cập nhật trọng số với tốc độ học (learning rate của Critic) là:
Cập nhật cho Actor ()
Khác với Critic, mạng Actor không đi giải bài toán giảm thiểu sai số dự đoán, mà nó hướng tới mục tiêu tối đa hóa hàm phần thưởng tích lũy kỳ vọng đã được định nghĩa ban đầu. Do đó, chúng ta áp dụng phương pháp Tăng gradient (Gradient Ascent). Dựa trên định lý Gradient chính sách (Policy Gradient Theorem) kết hợp với việc thay thế hàm Lợi thế bằng sai số toán học thu được từ Critic, hướng tăng gradient cho tham số của Actor là:
Với mỗi mẫu dữ liệu thực tế thu được tại bước , quy tắc cập nhật trọng số với tốc độ học (learning rate của Actor) là:
Ý nghĩa của sự phối hợp cập nhật
Nếu (Khen thưởng): Hành động mang lại kết quả tốt hơn Critic mong đợi. Biểu thức cập nhật sẽ cộng thêm một lượng thuận chiều với , làm tăng xác suất Actor sẽ chọn lại hành động này tại trạng thái trong tương lai. Đồng thời, giá trị mục tiêu lớn hơn dự kiến sẽ khiến mạng Critic cập nhật để tăng ước lượng giá trị lên.
Nếu (Phạt): Hành động tệ hơn dự kiến. Biểu thức cập nhật của Actor sẽ đổi dấu thành trừ, làm giảm xác suất chọn lại hành động này. Song song đó, Critic cũng nhận ra mình đã đánh giá quá cao trạng thái này và cập nhật để giảm ước lượng giá trị xuống.
Chi tiết thuật toán

Init Actor and Critic networks, with learning rates
for each episode do
while not terminal do
sample , observe
// critic step
// tính Advantage
// Minimize Mean Square Error
// actor step
// Policy gradient
end while
end for
Thảo luận mở rộng
Độ chệch và Cập nhật hai tốc độ (Bias & Two Time-Scale Convergence)
Việc thay thế bằng mục tiêu TD giúp giảm mạnh phương sai nhưng lại đưa vào Độ chệch (Bias). Nguồn gốc của độ chệch đến từ:
Sai số xấp xỉ: chỉ là hàm xấp xỉ bằng mạng thần kinh chứ không phải hàm thực tế .
Bootstrapping: Sử dụng một giá trị ước lượng của trạng thái kế tiếp để cập nhật cho trạng thái hiện tại ("dùng ước lượng để cập nhật ước lượng").
Để triệt tiêu độ chệch này và đảm bảo thuật toán hội tụ về nghiệm tối ưu, ta bắt buộc phải áp dụng cơ chế Cập nhật hai tốc độ (Two Time-Scale Update). Theo đó, mạng Critic phải học nhanh hơn đáng kể so với mạng Actor nhằm bám sát hàm giá trị thực tế nhanh nhất có thể:
Entropy Regularization
Trong giai đoạn đầu của quá trình huấn luyện, mạng Actor dễ rơi vào trạng thái hội tụ sớm (Premature Convergence). Tức là, nếu một vài hành động ngẫu nhiên ban đầu mang lại phần thưởng dương, Actor sẽ nhanh chóng tăng xác suất của các hành động đó lên mức tuyệt đối (). Điều này khiến phân phối chính sách bị "co cụm", triệt tiêu khả năng khám phá không gian môi trường (Exploration) và khiến tác nhân bị mắc kẹt tại các cực trị địa phương (Local Minima).
Để giải quyết tình trạng chính sách hội tụ sớm vào các cực trị địa phương (Premature Convergence) , ta thêm đại lượng Entropy Shannon vào hàm mục tiêu của Actor nhằm khuyến khích việc khám phá không gian môi trường. Tại một trạng thái , Entropy của phân phối chính sách được định nghĩa là:
Hàm mục tiêu tổng thế (Total Objective Function) cần tối đa hóa lúc này trở thành:
Trong đó, là Hệ số Entropy (Entropy Coefficient) điều khiển sự cân bằng giữa Khám phá (Exploration) và Khai thác (Exploitation):
Nếu quá cao: Phân phối hành động tiệm cận về phân phối đều (Uniform Distribution), tác nhân hành động hỗn loạn và không thể hội tụ.
Nếu quá thấp hoặc bằng 0: Tác nhân dễ bị "lùi bước" vào các chiến thuật dưới mức tối ưu quá sớm.
Khai triển Gradient của Entropy theo tham số :
Để áp dụng phương pháp tăng gradient, ta tính đạo hàm trực tiếp của thành phần Entropy bằng quy tắc đạo hàm tích :
Sử dụng mẹo Đạo hàm Log ngược loại để đưa về dạng kỳ vọng lấy mẫu: , ta được:
Do đó, quy tắc cập nhật độ dốc cho Actor tại mỗi bước thời gian khi có thêm Entropy Regularization là:
Từ TD(0) đến TD(n) và Ước lượng Lợi thế Tổng quát (GAE)
Mô hình Actor-Critic cơ bản sử dụng sai số TD 1 bước—gọi là TD(0):
Phương pháp này có phương sai cực thấp vì nó chỉ phụ thuộc vào một phần thưởng thực tế . Tuy nhiên, nó có độ chệch (bias) rất cao vì mục tiêu cập nhật phụ thuộc hoàn toàn vào mức độ chính xác của hàm ước lượng tại thời điểm đó.
Để dung hòa mối quan hệ đánh đổi phương sai - độ chệch (Bias-Variance Trade-off), ta mở rộng không gian nhìn trước ra bước thời gian—gọi là TD() Return. Mục tiêu phần thưởng tích lũy lúc này được viết dưới dạng:
Hàm lợi thế -bước tương ứng sẽ là: .
Ước lượng Lợi thế Tổng quát (Generalized Advantage Estimation - GAE)
Thay vì cố định một con số cứng nhắc, thuật toán sử dụng giải pháp GAE bằng cách lấy trung bình trọng số hình học của tất cả các hàm lợi thế -bước, được điều phối qua một siêu tham số suy giảm :
Khi triển khai toán học khai triển chuỗi, một tính chất đệ quy cực kỳ đẹp đẽ xuất hiện thông qua việc xếp chồng các chuỗi sai số TD 1-bước ():
Cơ chế Đệ quy ngược (Backward Recursion)
Nếu tính toán chuỗi tổng trên một cách tuần tiến từ thời điểm trở đi, độ phức tạp tính toán sẽ là do phải duyệt lại tương lai tại mỗi bước. Để tối ưu hóa tài nguyên về mức tuyến tính , thuật toán triển khai cơ chế Đệ quy ngược (Backward Recursion) từ cuối một quỹ đạo dữ liệu () lộn ngược về thời điểm đầu ():
Với điều kiện biên tại thời điểm kết thúc quỹ đạo hoặc trạng thái terminal là .
Thuật toán: Actor-Critic với Cập nhật Tích lũy (Batch A2C)
Khởi tạo: Bộ tham số mạng Actor , bộ tham số mạng Critic , các tốc độ học , hệ số entropy , hệ số chiết khấu , và hệ số GAE .
Vòng lặp huấn luyện:
Bước 1: Thu thập trajectory (Forward Pass)
Đặt các biến tích lũy gradient về không: ,
Xóa bộ nhớ đệm lịch sử bước thời gian.
For to do:
Thực thi hành động
Nhận phần thưởng và trạng thái tiếp theo từ môi trường.
Lưu trữ dữ liệu bộ tuple vào bộ đệm.
Nếu gặp trạng thái kết thúc (terminal): Bẻ gãy vòng lặp thu thập.
Bước 2: Tính toán mục tiêu tương lai và Ước lượng GAE ngược (Backward Pass)
Khởi tạo giá trị bootstrap tại biên:
Khởi tạo biến tích lũy lợi thế:
For down to do:
Cập nhật giá trị đích thực tế -bước:
Tính toán sai số TD 1-bước cục bộ:
Tính toán lợi thế GAE đệ quy ngược:
Gán nhãn giá trị kế tiếp cho bước sau:
Bước 3: Tích lũy Gradients (Accumulating Gradients)
Cộng dồn các đạo hàm riêng qua từng bước thời gian trong Batch vào biến tích lũy tổng:
Bước 4: Thực thi Cập nhật Tích lũy Toàn cục (Global Accumulated Update)
Sau khi kết thúc việc duyệt ngược và tích lũy qua toàn bộ Batch, bộ tham số của hai mạng thần kinh được tối ưu hóa đồng loạt theo quy tắc:
Ý nghĩa: Toàn bộ các hướng dịch chuyển của vector trọng số trên đồ thị lỗi đã được tối ưu hóa đồng bộ dựa trên thông tin tổng hòa của cả một chuỗi hành động trong quá khứ, giúp giảm tối đa hiện tượng nhiễu stochastic và tăng tốc độ hội tụ của mô hình.
Demo
More from AI & ML
- RL - Từ TD-Learning đến Q-Learning
- Reinforcement Learning - Học theo Chính Sách (Policy Gradient)
- JEPA: Kiến Trúc Dự Đoán Không Gian Ẩn và Con Đường Đến Trí Tuệ Thực Sự
- Reinforcement Learning - Bài mở đầu
- Multi-Armed Bandits: Từ Greedy đến UCB rồi đến Exp3
- Cơ bản về ANN - Artificial Neural Network
- Aritificial Neural Network: Bản chất Xác suất phía sau Bài toán Hồi quy
- NEAT (NeuroEvolution of Augmenting Topologies)- Nhiệm vụ hạ cánh tàu vũ trụ
- Q-Learning căn bản - Nhiệm vụ hạ cánh tàu vũ trụ
- Singular Value Decomposition (SVD) Demo
- Thuật toán K-Means demo
Comments
No comments yet. Be the first to comment!