RL - Từ TD-Learning đến Q-Learning
Trong bài viết trước, chúng ta đã chứng minh qua định lý Banach được rằng toán tử Bellman là một ánh xạ co (contraction mapping) và vì thế sẽ tồn tại một điểm cố định duy nhất :
với:
Trong đó:
: Giá trị của cặp trạng thái - hành động hiện tại.
: Phần thưởng tức thì (reward) nhận được sau khi thực hiện hành động tại trạng thái .
: Hệ số chiết khấu (discount factor), với . Đây là yếu tố then chốt để thỏa mãn điều kiện của một ánh xạ co.
: Giá trị ước tính tốt nhất có thể đạt được từ trạng thái kế tiếp .
: Giá trị kỳ vọng dựa trên xác suất chuyển trạng thái .
Từ điểm cố định này, chúng ta có thể xác định Chính sách tối ưu (Optimal Policy) bằng cách chọn hành động mang lại giá trị lớn nhất tại mỗi trạng thái:
Về mặt ý nghĩa, đại diện cho tổng phần thưởng tích lũy kỳ vọng lớn nhất mà agent có thể nhận được từ bất kỳ cặp trạng thái - hành động nào. Với mọi chính sách khác, ta luôn có:
Điều này lý giải tại sao lại tối ưu. Tuy nhiên, theo lý thuyết, toán tử yêu cầu tính kỳ vọng trên toàn bộ không gian trạng thái và hành động:
Nhưng trong thực tế, chúng ta đối mặt với hai vấn đề:
Chúng ta thường không biết xác suất chuyển trạng thái .
Chúng ta chỉ quan sát được các mẫu (samples) cụ thể dạng , thay vì tính toán trên toàn bộ phân phối vì không gian bài toán có thể siêu lớn.
Phương pháp Temporal Difference (TD) Learning: Thay kỳ vọng bằng samples
Như đã nêu phần trước, trong đa số các môi trường phức tạp (như điều khiển robot hay chơi game), chúng ta hoàn toàn không biết mô hình này (Model-free). Vì thế, thay vì ngồi tính toán mọi khả năng có thể xảy ra theo lý thuyết, chúng ta để Agent thực sự tương tác với môi trường rồi:
Quan sát thực tế: Khi Agent thực hiện hành động tại trạng thái , nó nhận về một kết quả thực tế duy nhất là cặp .
Thay thế kỳ vọng: Thay vì tính trung bình cộng của tất cả các kịch bản tương lai có thể xảy ra (kỳ vọng ), chúng ta lấy chính mẫu thực tế vừa thu được để đại diện cho giá trị của tương lai.
Và đó cũng chính là ý tưởng của TD Learning (sự khác biệt về thời gian) với hai tính chất chủ đạo:
Tính chất Temporal (Thời gian): Tại thời điểm , Agent có một ước lượng ban đầu là . Để kiểm chứng ước lượng này, Agent phải đợi thời gian trôi qua đến bước để thu thập thêm dữ liệu thực tế từ môi trường.
Tính chất Difference (Sự khác biệt): Sau khi có thông tin tại , Agent so sánh sự chênh lệch giữa cái mình đã biết và cái mình vừa thấy. Sự khác biệt này được gọi là TD Error:
TD Learning chính là quá trình "lấy sai số của tương lai để sửa chữa nhận thức ở hiện tại". Chúng ta không thông tin hoàn hảo ngay từ đầu; thay vào đó, Agent sẽ liên tục tinh chỉnh các giá trị sao cho sự khác biệt giữa các thời điểm (Temporal Difference) dần triệt tiêu về 0, tiến tới điểm cố định mà định lý Banach đã dự báo.
Thuật toán Q-Learning
Như đã phân tích, TD Learning là một tư duy cập nhật bằng cách dùng sự chênh lệch giữa hai thời điểm để học. Khi áp dụng tư duy của TD Learning trực tiếp vào hàm , chúng ta sẽ đi đến thuật toán Q-Learning theo các bước logic sau:
Bước 1: Tính sai số TD
Chúng ta biết rằng theo lý thuyết, tại điểm cố định , sai số giữa 2 về của phương trình Bellman phải bằng . Trong thực tế, khi Agent tương tác và thu được một mẫu , sự chênh lệch (TD Error) xuất hiện:
Mục tiêu của chúng ta là đưa sai số về . Chúng ta định nghĩa hàm mất mát:
Lấy đạo hàm riêng theo :
(Lưu ý: Trong toán học chuẩn của Q-Learning, chúng ta coi Target là một hằng số tại thời điểm cập nhật, nên không lấy đạo hàm thành phần ).
Bước 2: Công thức cập nhật (Update Rule)
Áp dụng quy tắc Gradient Descent: , đạo hàm vừa tính vào để đưa ra công thức cập nhật:
Trong đó:
: Giá trị cũ mà chúng ta đang lưu trữ trong bảng (hoặc mạng thần kinh).
(Learning rate): Tốc độ học, quyết định chúng ta tin vào trải nghiệm mới vừa thu được bao nhiêu phần trăm ().
: Chính là cách chúng ta xấp xỉ toán tử co bằng dữ liệu mẫu. Nó đại diện cho toán tử Bellman tối ưu mà chúng ta đã chứng minh là ánh xạ co.
Áp dụng Q-Learning cho bài toán Grid-World
Bài toán Grid-World
Hãy tưởng tượng một Agent đang ở trong một mê cung ô lưới 4×4 (GridWorld) như hình dưới đây:
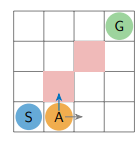
Mục tiêu của Agent là tìm đường đến G mà có thể tối đa hóa phần thưởng nhận được với các thông tin sau:
S (Start): Điểm bắt đầu.
G (Goal): Đích đến - nơi Agent nhận được phần thưởng hậu hĩnh (). Khi đến đích thì giả lập kết thúc.
Ô đỏ: Đi vào sẽ bị phạt nặng (phần thưởng )
Ô trắng: Đi vào sẽ bị phạt nhẹ (phần thưởng )
Luật chơi: Agent tại một ô bất kỳ có thể đi 1 trong 4 hướng: Lên, Xuống, Trái, Phải để sang ô mới.
Trong bài toán Grid-World mà chúng ta đã định nghĩa, không gian trạng thái (số ô trên lưới) và không gian hành động (Lên, Xuống, Trái, Phải) là hữu hạn và đủ nhỏ. Do đó, chúng ta sẽ sử dụng cấu trúc Tabular Q-Learning. Chúng ta sẽ khởi tạo một Bảng Q (Q-Table) dùng để lưu các giá trị rời rạc. Đây là cấu trúc lưu trữ Key-Value dạng (x,y,action) -> Value , trong đó:
Vị trí
x,ycủa Agent trên lưới 2D chính là trạng thái .Bốn hướng di chuyển cụ thể:
up,down,left,rightchính là hành độngValuelà giá trị thực đại diện cho "chất lượng" của hành động đó tại vị trí đó
Demo
More from AI & ML
- RL - Phương pháp Actor Critic
- Reinforcement Learning - Học theo Chính Sách (Policy Gradient)
- JEPA: Kiến Trúc Dự Đoán Không Gian Ẩn và Con Đường Đến Trí Tuệ Thực Sự
- Reinforcement Learning - Bài mở đầu
- Multi-Armed Bandits: Từ Greedy đến UCB rồi đến Exp3
- Cơ bản về ANN - Artificial Neural Network
- Aritificial Neural Network: Bản chất Xác suất phía sau Bài toán Hồi quy
- NEAT (NeuroEvolution of Augmenting Topologies)- Nhiệm vụ hạ cánh tàu vũ trụ
- Q-Learning căn bản - Nhiệm vụ hạ cánh tàu vũ trụ
- Singular Value Decomposition (SVD) Demo
- Thuật toán K-Means demo
Comments
No comments yet. Be the first to comment!