Reinforcement Learning - Bài mở đầu
Nhân dịp mình có làm việc cùng với một nhóm bạn về Reinforcement Learning, mình muốn viết một series về RL chia sẻ với các bạn.
Reinforcement Learning là gì?
Về bản chất, Reinforcement Learning (RL) là một nhánh của Machine Learning tập trung vào việc ra quyết định. Khác với Học có giám sát (Supervised Learning) dựa trên dữ liệu được gán nhãn sẵn, RL học thông qua sự tương tác. Hãy tưởng tượng bạn đặt một robot vào trong một mê cung. Bạn không cho nó bản đồ, cũng không bảo nó phải rẽ trái hay rẽ phải tại mỗi ngã rẽ. Robot chỉ biết một mục tiêu duy nhất: Tìm đường ra.
Nếu nó đi vào đường cụt, nó nhận một điểm phạt (-1).
Nếu nó tìm thấy lối ra, nó nhận một phần thưởng lớn (+100).
Qua hàng ngàn lần thử và sai, robot sẽ tự rút ra được một tập hợp các quy tắc để tối đa hóa số điểm nhận được. Đó chính là cách RL vận hành: Học từ phản hồi của môi trường thay vì học từ hướng dẫn trực tiếp.
Các thành phần của RL
Một hệ thống RL luôn xoay quanh sự tương tác giữa Tác nhân (Agent) và Môi trường (Environment).
Agent (Tác nhân)
Đây là "bộ não" của hệ thống, thực thể thực hiện việc quan sát và đưa ra quyết định. Agent không biết trước quy luật của môi trường, nó chỉ có thể học thông qua việc thực hiện các hành động.
Environment (Môi trường)
Là tất cả những gì nằm bên ngoài Agent. Môi trường tiếp nhận hành động từ Agent, thay đổi trạng thái và gửi lại các tín hiệu phản hồi.
State - Trạng thái ()
Mô tả tình trạng hiện tại của Agent trong môi trường.
Ví dụ: Trong trò chơi cờ vua, là vị trí của tất cả các quân cờ trên bàn tại một thời điểm cụ thể.
Action - Hành động ()
Danh sách tất cả các quyết định mà Agent có thể thực hiện tại một trạng thái.
Ví dụ: Tại trạng thái hiện tại, con robot có thể chọn đi thẳng, rẽ trái hoặc rẽ phải.
Reward - Phần thưởng ()
Đây là thước đo duy nhất để Agent biết mình đang làm tốt hay tệ. Reward là một con số cụ thể được trả về ngay sau khi Agent thực hiện một hành động.
Lưu ý: Mục tiêu của Agent không phải là nhận phần thưởng lớn nhất tức thì, mà là tối đa hóa tổng phần thưởng tích lũy được trong dài hạn.
Policy - Chiến lược ()
Policy là "cuốn cẩm nang" của Agent. Nó là một hàm số hoặc một bảng tra cứu giúp Agent quyết định nên thực hiện hành động nào khi đang ở trạng thái . Mục tiêu cuối cùng của chúng ta khi huấn luyện RL là tìm ra một Policy tối ưu ().
Mô hình hóa bài toán RL và Hàm Mục Tiêu
Hình phía dưới mô tả mối quan hệ giữa Agent và Environment:
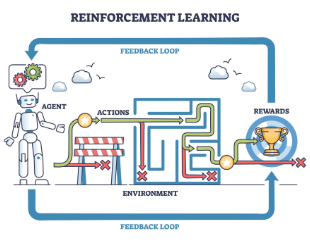
Mối quan hệ chúng diễn ra theo một vòng lặp thời gian :
Tại thời điểm , Agent quan sát trạng thái .
Dựa trên chiến lược , Agent thực hiện hành động - hành động tại thời điểm được chọn ngẫu nhiên dựa trên phân phối xác suất của chiến lược (policy) với trạng thái hiện tại là .
Môi trường tiếp nhận , phản hồi lại một phần thưởng và chuyển sang trạng thái mới .
Vòng lặp này tạo ra một chuỗi kéo dài:
Hàm Mục Tiêu
Agent không tối ưu hóa phần thưởng tức thì (), mà tối ưu hóa tổng phần thưởng tích lũy kể từ thời điểm hiện tại đến tương lai, ký hiệu là .
Vì phần thưởng ở xa thường có độ rủi ro hoặc giá trị thấp hơn hiện tại, chúng ta đưa hệ số chiết khấu vào công thức:
Nếu : Agent chỉ quan tâm đến phần thưởng ngay lập tức.
Nếu : Agent coi trọng phần thưởng tương lai gần bằng phần thưởng hiện tại.
Trong các bài toán RL, Agent thường hoạt động trong các môi trường có thể kéo dài vô tận (Infinite Horizon), ví dụ như một con robot vận hành trong nhà máy hoặc một chương trình điều khiển máy bay. Việc đưa vào công thức có một lợi điểm là làm cho giá trị của hội tụ (chuỗi hình học) thay vì tiến ra . Vì nếu mọi chiến lược đều dẫn đến tổng điểm là vô cùng, Agent sẽ không thể so sánh được chiến lược nào tốt hơn chiến lược nào. Máy tính cũng không thể xử lý các giá trị vô hạn này trong các phép toán tối ưu hóa.
Chúng ta định nghĩa Hàm Mục Tiêu dưới dạng kỳ vọng:
Trong đó:
(Trajectory): Là một chuỗi các trạng thái và hành động diễn ra.
: Giá trị kỳ vọng khi Agent hành động theo chiến lược .
(Gamma): Hệ số chiết khấu để ưu tiên phần thưởng gần hơn.
Tóm lại:
và tạo nên không gian bài toán.
là thước đo thành công (tín hiệu phản hồi).
là biến số mà chúng ta cần tối ưu hóa.
Hàm mục tiêu là đích đến: Agent sẽ liên tục điều chỉnh để giá trị đạt mức cao nhất có thể.
Markov Decision Process (MDP)
Trong một hệ thống thông thường, tương lai phụ thuộc vào mọi thứ đã xảy ra trong quá khứ. Nếu muốn dự đoán trạng thái tiếp theo , ta phải xét một chuỗi lịch sử (History) dài dằng dặc từ :
Tính chất Markov giả định rằng: Trạng thái hiện tại đã chứa đựng đầy đủ thông tin cần thiết của quá khứ để quyết định tương lai. Khi đó, công thức rút gọn chỉ còn:
Nói cách khác, để quyết định bước tiếp theo, bạn chỉ cần nhìn vào trạng thái hiện tại mà không cần quan tâm đến các chuỗi hành động đã xảy ra như thế nào trước đó. Vì thế chúng ta có thể tận dụng được các ưu điểm mà tính chất này mang lại:
Giải phóng bộ nhớ: Agent không cần quan tâm nó đã đi qua những đâu để tới được đây. Nó chỉ cần biết "Tôi đang ở đâu?" () để chọn hành động ().
Nếu không có tính chất này, không gian trạng thái sẽ bùng nổ theo thời gian, khiến máy tính không bao giờ xử lý nổi.
Để định nghĩa hoàn chỉnh một môi trường Markov, ta cần 5 tham số:
(State space): Tập hợp tất cả các trạng thái có thể có. Tập hợp này có thể là hữu hạn (các ô trong bàn cờ) hoặc vô hạn (tọa độ của một chiếc xe tự lái).
(Action space): Tập hợp các hành động Agent có thể thực hiện tại mỗi trạng thái.
(Transition Probability): Xác suất chuyển trạng thái . Nó mô tả sự "ngẫu nhiên" của môi trường (ví dụ: robot muốn đi thẳng nhưng sàn trơn nên có 10% bị lệch phải).
(Reward Function): Hàm phần thưởng . Là số điểm mà Agent nhận được khi thực hiện hành động để chuyển từ trạng thái sang .
(Discount Factor): Hệ số chiết khấu dùng để xác định mức độ quan trọng của các phần thưởng trong tương lai so với phần thưởng tức thì.
Nếu gần bằng 0: Agent chỉ quan tâm đến phần thưởng ngay trước mắt.
Nếu gần bằng 1: Agent sẽ nhìn xa hơn, nó sẵn sàng chịu khổ ở hiện tại để đạt được phần thưởng lớn ở cuối con đường.
Toán tử Bellman - Bellman Operator
Khi một Agent hoạt động trong môi trường MDP, nó cần một công cụ để đánh giá: "Đứng ở đây thì tương lai sẽ tốt đến mức nào?"
Hàm giá trị (Value Function)
Hàm giá trị là một ước tính về tổng lợi nhuận chiết khấu () mà Agent có thể nhận được trong tương lai. Có hai loại hàm giá trị cơ bản:
Hàm giá trị trạng thái : Ước tính giá trị của một trạng thái khi tuân theo chiến lược .
Hàm giá trị hành động : Ước tính giá trị của việc thực hiện hành động tại trạng thái , sau đó mới tuân theo chiến lược .
Toán tử Bellman ()
Hãy tưởng tượng không gian của tất cả các hàm giá trị khả thi là một không gian vector. Toán tử Bellman () là một phép biến đổi ánh xạ một hàm giá trị này sang một hàm giá trị khác. Trong toán học, một toán tử là một thực thể nhận một hàm số làm đầu vào và trả về một hàm số khác. Toán tử Bellman đóng vai trò là "người hiệu chỉnh" hàm giá trị.
Giả sử chúng ta có một hàm giá trị (có thể là một phỏng đoán ngẫu nhiên ban đầu). Toán tử sẽ tác động lên để tạo ra một hàm mới thông qua công thức:
Trong đó:
: Phần thưởng tức thì khi thực hiện hành động .
: Giá trị kỳ vọng của tương lai (đã chiết khấu) dựa trên phỏng đoán hiện tại của chúng ta về các trạng thái kế tiếp. Tính chất Markov được thể hiện rõ ở đây, chúng ta chỉ cần biết trạng thái hiện tại để tính toán.
: Đây là bước quan trọng nhất. Toán tử này "nhìn" vào tất cả các hành động khả thi và chọn hành động hứa hẹn nhất.
Toán tử Bellman dựa trên việc chia nhỏ bài toán lớn thành các bài toán con lồng nhau.
Giá trị hôm nay = Phần thưởng hôm nay + Giá trị ngày mai.
Sự chuyển đổi này chỉ khả thi khi hệ thống có tính chất Markov. Nó cho phép chúng ta tin rằng giá trị ở trạng thái kế tiếp đã đại diện đầy đủ cho mọi khả năng có thể xảy ra sau đó, bất kể Agent đã đến bằng cách nào. Nhờ Markov, toán tử Bellman không cần quan tâm đến các quỹ đạo (trajectories) phức tạp trong quá khứ mà chỉ tập trung vào xác suất chuyển trạng thái . Nếu không có Markov, giá trị của có thể thay đổi tùy thuộc vào việc bạn đến đó từ con đường nào, và khi đó phương trình Bellman sẽ bị đổ vỡ vì không thể thiết lập được mối quan hệ đệ quy cố định.
Nền tảng của hội tụ
Đến đây, câu hỏi quan trọng nhất là: "Làm sao để máy tính tìm được (giá trị tối ưu) một cách tự động?"
Như đã trình bày phía trên, Toán tử Bellman tối ưu là một "cỗ máy" nhận vào một hàm giá trị và trả về một hàm giá trị mới tốt hơn:
Khái niệm Ánh xạ co (Contraction Mapping)
Để hiểu tại sao thuật toán hội tụ, chúng ta cần đo khoảng cách giữa hai hàm giá trị và . Chúng ta sử dụng chuẩn vô hạn ( norm), tức là sai lệch lớn nhất giữa hai hàm tại bất kỳ trạng thái nào:
Một toán tử được gọi là ánh xạ co nếu sau khi áp dụng nó, khoảng cách giữa hai điểm luôn bị thu hẹp lại. Đối với toán tử Bellman, người ta đã chứng minh được rằng:
Chúng ta cùng đi vào chứng minh khá thú vị này:
Ta có theo định nghĩa:
Một tính chất quan trọng của hàm là: .
Áp dụng tính chất này để xét hiệu giữa và :
Khi trừ hai biểu thức, thành phần phần thưởng (không phụ thuộc vào hay ) sẽ bị triệt tiêu:
Đưa hằng số dương ra ngoài dấu trị tuyệt đối:
Ta biết rằng . Thay vào biểu thức trên:
Vì là một hằng số không phụ thuộc vào , ta đưa nó ra ngoài tổng:
Trong MDP, (tổng xác suất chuyển sang các trạng thái kế tiếp luôn bằng 1). Do đó:
Vì bất đẳng thức trên đúng với mọi trạng thái , nên nó cũng đúng với giá trị lớn nhất của vế trái (tức là chuẩn vô hạn):
Tiếp theo, ta lại có hệ số chiết khấu theo quy ước, do đó khi cập nhật hàm giá trị, sai số từ các trạng thái tương lai đã bị triệt tiêu đi một tỷ lệ . Qua mỗi lần lặp, sai số này càng ngày càng nhỏ lại. Từ đây ta kết luận toán tử Bellman trên hàm giá trị V là một ánh xạ co.
Định lý điểm cố định Banach (Banach Fixed-Point Theorem)
Đây là tư tưởng nền móng của toàn bộ lý thuyết. Định lý phát biểu rằng: Trong một không gian metric đầy đủ (như không gian các hàm giá trị hữu hạn), nếu là một ánh xạ co, thì:
Tồn tại duy nhất một điểm cố định sao cho . Đây chính là nghiệm tối ưu mà chúng ta tìm kiếm.
Sự hội tụ toàn cục: Nếu bạn bắt đầu từ bất kỳ hàm giá trị ngẫu nhiên nào và lặp lại liên tục , dãy số này chắc chắn sẽ hội tụ về .
Nếu không có điều này, RL chỉ là một chuỗi các thử nghiệm may rủi. Nhưng nhờ có Ánh xạ co và Định lý Điểm cố định Banach:
Đảm bảo thành công: Chúng ta biết chắc chắn rằng các thuật toán như Value Iteration hay Q-Learning sẽ không chạy vòng quanh vô tận mà sẽ hội tụ về đáp án đúng.
Tính duy nhất: Bài toán RL chỉ có một lời giải tối ưu duy nhất (về mặt hàm giá trị), giúp Agent không bị phân tâm giữa các mục tiêu mâu thuẫn.
Các thuật toán Reinforcement Learning
Trong thực tế, Agent hiếm khi có sẵn "bản đồ toán học" (MDP hoàn chỉnh) của thế giới. Nó phải học thông qua trải nghiệm. Dựa trên cách Agent sử dụng toán tử Bellman và mục tiêu tối ưu, chúng ta chia RL thành các dòng chính:
Model-Based vs Model-Free
Model-Based: Agent cố gắng học/xây dựng một mô hình về môi trường (đoán xem và là gì). Nếu có mô hình, nó có thể "lập kế hoạch" (planning) trong đầu trước khi hành động.
Model-Free (Phổ biến nhất): Agent không quan tâm đến việc học mô hình môi trường. Nó chỉ tập trung vào việc học xem hành động nào mang lại giá trị cao nhất thông qua trải nghiệm trực tiếp.
Value-Based (Dựa trên giá trị)
Đây là họ thuật toán áp dụng trực tiếp kết quả từ Toán tử Bellman tối ưu. Agent cố gắng học hàm giá trị hành động .
Tư duy: "Nếu tôi biết giá trị của mọi hành động, tôi chỉ cần chọn cái lớn nhất."
Đại diện: Q-Learning. Khi kết hợp với mạng nơ-ron sâu để xử lý không gian trạng thái lớn, chúng ta có DQN (Deep Q-Network).
Policy-Based (Dựa trên chiến lược)
Thay vì học hàm giá trị rồi mới suy ra hành động, họ thuật toán này tối ưu trực tiếp chiến lược .
Tư duy: "Tôi sẽ điều chỉnh các tham số của hàm sao cho xác suất chọn các hành động có phần thưởng cao ngày càng tăng lên."
Đại diện: REINFORCE, Policy Gradient. Phương pháp này rất mạnh khi không gian hành động là liên tục (như điều khiển lực cánh tay robot).
Actor-Critic
Đây là đỉnh cao của các thuật toán hiện đại, kết hợp cả hai ưu điểm trên:
Critic (Người phê bình): Học hàm giá trị để đánh giá xem trạng thái hiện tại tốt hay xấu (Value-based).
Actor (Diễn viên): Học chiến lược để ra quyết định, dựa trên sự "phê bình" của Critic để cải thiện (Policy-based).
Đại diện: PPO (Proximal Policy Optimization) – thuật toán cực kỳ ổn định được OpenAI sử dụng rộng rãi, hay A3C.
More from AI & ML
- RL - Từ TD-Learning đến Q-Learning
- RL - Phương pháp Actor Critic
- Reinforcement Learning - Học theo Chính Sách (Policy Gradient)
- JEPA: Kiến Trúc Dự Đoán Không Gian Ẩn và Con Đường Đến Trí Tuệ Thực Sự
- Multi-Armed Bandits: Từ Greedy đến UCB rồi đến Exp3
- Cơ bản về ANN - Artificial Neural Network
- Aritificial Neural Network: Bản chất Xác suất phía sau Bài toán Hồi quy
- NEAT (NeuroEvolution of Augmenting Topologies)- Nhiệm vụ hạ cánh tàu vũ trụ
- Q-Learning căn bản - Nhiệm vụ hạ cánh tàu vũ trụ
- Singular Value Decomposition (SVD) Demo
- Thuật toán K-Means demo
Comments
No comments yet. Be the first to comment!